 1. 基本概念与快速开始
1. 基本概念与快速开始
# 1.1 基本概念
LlamaIndex(之前被称为 GPT Index)是一个用于构建基于大语言模型(LLM)的信息检索系统的开源框架。核心功能是帮助用户从不同的数据源(如文本文件、数据库、API 等)中快速获取、处理和分析信息,以便于与 LLM 交互时提供上下文和更精确的回答。
官方文档:
- Python 文档地址:https://docs.llamaindex.ai/en/stable/ (opens new window)
- Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/ (opens new window)
# 核心模块
LlamaIndex工作流程与核心模块如下所示:
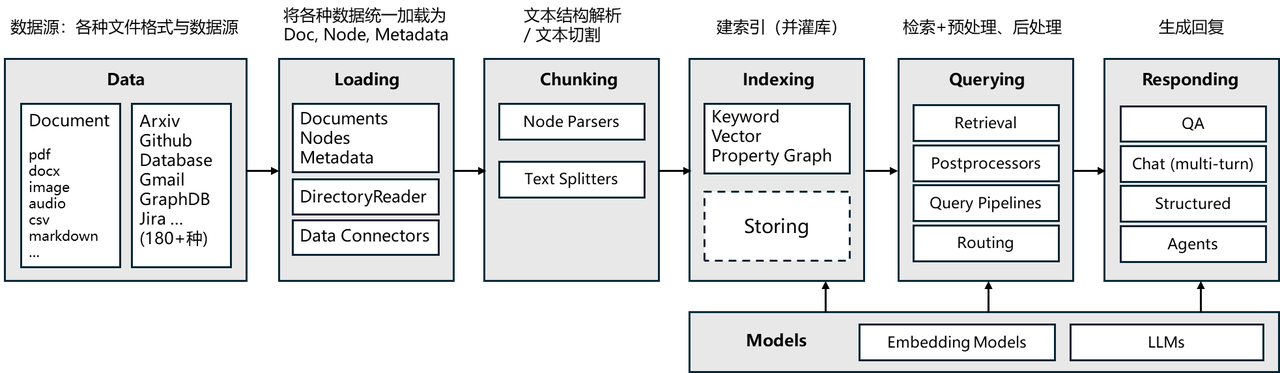
# 核心组件
| 组件 | 说明 |
|---|---|
| Documents | 数据的容器,包含文本内容和元数据 |
| Nodes | 文档的原子单元,是 Document 的分块 |
| Embeddings | 文本的向量表示,用于语义相似度计算 |
| Index | 组织和存储 Nodes 的数据结构 |
| Retriever | 根据查询检索相关 Nodes |
| Query Engine | 端到端的问答流程封装 |
| Response Synthesizer | 将检索结果合成最终回答 |
# 1.2 快速开始
# 安装
pip install llama-index
1
LlamaIndex 默认使用 OpenAI 的模型,需要配置环境变量:
export OPENAI_API_KEY="your-api-key"
1
Windows PowerShell:
$env:OPENAI_API_KEY="your-api-key"
1
# 五行代码实现 RAG
先试一下 LlamaIndex 官网的示例,只需要五行代码即可实现一个完整的 RAG 系统:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 加载文档
documents = SimpleDirectoryReader("data").load_data()
# 2. 构建索引
index = VectorStoreIndex.from_documents(documents)
# 3. 创建查询引擎
query_engine = index.as_query_engine()
# 4. 执行查询
response = query_engine.query("Llama 2有多少参数?")
print(response)
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
编辑 (opens new window)
上次更新: 2025/12/19, 15:17:48
