 4.编码器
4.编码器
# 4.1 编码器的结构

上图为 Transformer 整体架构,左侧为编码器(Encoder),右侧为解码器(Decoder)。
编码器是Transformer的核心组件,负责将输入序列转换为上下文表示。编码器由多个编码器层(Encoder Layer)组成,每个编码器层包含两个子层:
- 多头自注意力(Multi-Head Self-Attention):让每个词元"看到"序列中的所有其他词元,捕捉词与词之间的依赖关系
- 前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换,增强模型的表达能力
# 4.2 注意力机制
在介绍多头自注意力之前,先来了解注意力机制的核心思想。
# 4.2.1 直观理解
想象你在阅读一段话时,理解某个词的含义往往需要关注句子中的其他词。例如:
"小明把苹果放进了冰箱,因为它坏了。"
理解"它"指的是什么,需要"注意"到前面的"苹果"。注意力机制模拟的就是这种能力——让模型学会关注输入中最相关的部分。
# 4.2.2 缩放点积注意力
注意力机制的核心是三个向量:
- Query(查询):当前词的"问题",表示"我需要什么信息?"
- Key(键):其他词的"标签",表示"我能提供什么信息?"
- Value(值):其他词的"内容",表示"我的实际信息是什么?"
缩放点积注意力的计算公式如下:
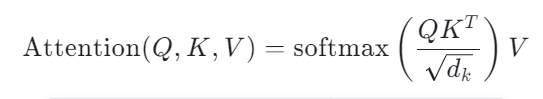
下面逐步理解公式的含义:
第一步:计算 QK^T(注意力分数)
由于 Q 向量与 K 向量形状相同,都是 N × d_k,所以需要对其中一个向量进行转置才能进行矩阵乘法。
QK^T 的几何学含义是计算 Q 向量与 K 向量的相似度(点积运算的几何学本质),最终得到一个 N × N 的相似度分数矩阵,矩阵中的每个元素表示对应词元之间的关联程度。
第二步:缩放
将点积结果除以 √d_k:
QK^T / √d_k
其中 d_k 是键向量的维度,1/√d_k 是缩放因子。这一步的作用是让点积结果的尺度稳定化,防止当 d_k 较大时点积值过大导致 Softmax 梯度消失,从而保证梯度合理,提升模型的训练效果。
第三步:Softmax 归一化
对缩放后的分数矩阵按行进行 Softmax 归一化:
softmax(QK^T / √d_k)
Softmax 将每一行的分数转换为概率分布(所有值在 0~1 之间,且每行之和为 1),表示当前词元对序列中各个词元的注意力权重。权重越大,说明该位置对当前词元越重要。
第四步:加权求和(乘以 V)
用注意力权重对 Value 向量进行加权求和:
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
注意力权重矩阵 [N × N] 与 V 矩阵 [N × d_v] 相乘,得到最终输出 [N × d_v]。
每个词元的输出是所有 Value 向量的加权组合,权重由注意力分数决定——关注度高的词元贡献更大,关注度低的词元贡献更小。这样,每个词元的表示都融合了它所"关注"的其他词元的信息。
# 4.2.3 自注意力(Self-Attention)
注意力机制与自注意力机制的区别:
- 注意力机制:关注外部信息,如翻译任务中源语言如何影响目标语言的生成
- 自注意力机制:关注内部信息,如当前句子中各个词元如何相互作用
在编码器中使用的是自注意力机制,其特点是 Q、K、V 都来自同一个输入序列。
为了方便理解,这里引用UP主自然卷小蛮 (opens new window)的图片:
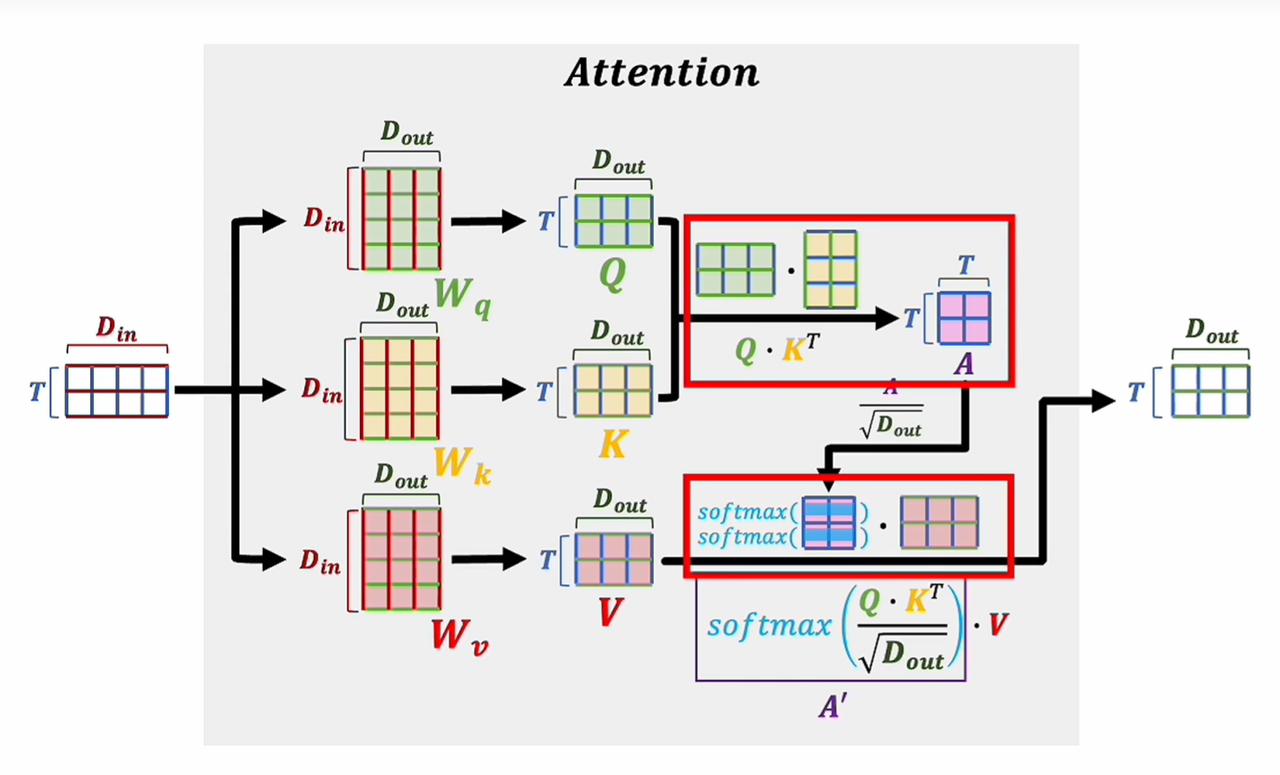
如图所示,输入向量通过三个可学习的权重矩阵进行线性变换:
Q = X · W_q
K = X · W_k
V = X · W_v
2
3
- W_q:将输入映射为 Query 向量
- W_k:将输入映射为 Key 向量
- W_v:将输入映射为 Value 向量
这三个矩阵的维度均为 D_in × D_out,是模型训练过程中学习到的参数。通过不同的权重矩阵,同一个输入可以被投影到不同的表示空间,分别承担"查询"、"被查询"和"提供信息"三种角色。
自注意力让序列中的每个词元都能"看到"并"关注"序列中的所有其他词元(包括自己),从而捕捉词元之间的依赖关系。
这与交叉注意力(Cross-Attention) 不同,后者的 Q 来自一个序列,而 K、V 来自另一个序列(如解码器中 Q 来自解码器,K、V 来自编码器输出)。
# 4.2.4 多头自注意力(Multi-Head Self-Attention)
不像普通注意力那样只计算一次,多头注意力会将词向量 + 位置编码后的输入馈送给多个注意力头并行计算,让模型能够同时从多个角度关注输入信息。
数据馈送给注意力头时有两种方式:
- 先分割再进入头:将词向量按维度分成多份,每个头处理一部分
- 进入头后再分割:完整向量进入每个头,头内部再做投影
虽然先分割看起来不太直观,但实际上这样做训练参数更少、训练更快。《Attention is All You Need》论文使用了 8 个头,下图仅展示 2 个头的示意(图片来源:自然卷小蛮 - 手推Transformer (opens new window)):
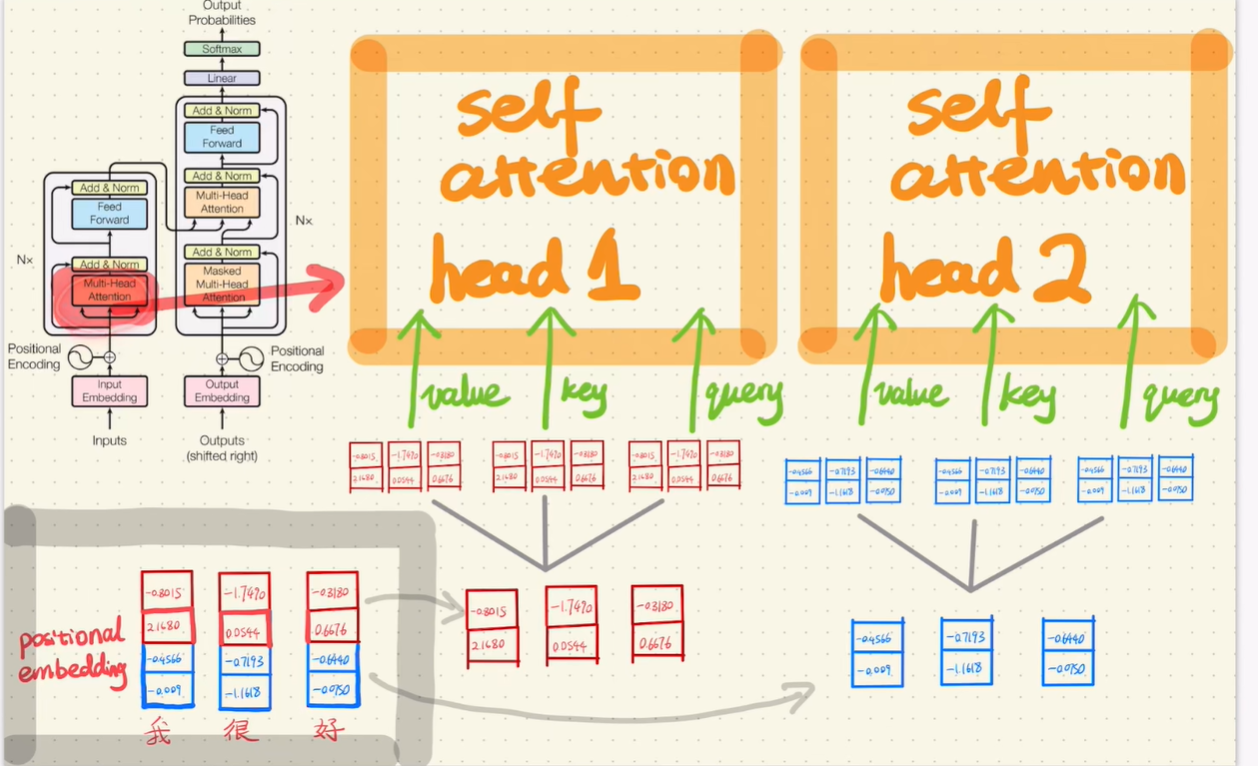
可以注意到,在 Transformer 的自注意力中,馈送给多头注意力的 Query、Key、Value 仅仅是将同一份输入数据复制了三份,然后分别通过不同的权重矩阵进行投影,从而让同一个输入承担三种不同的角色。
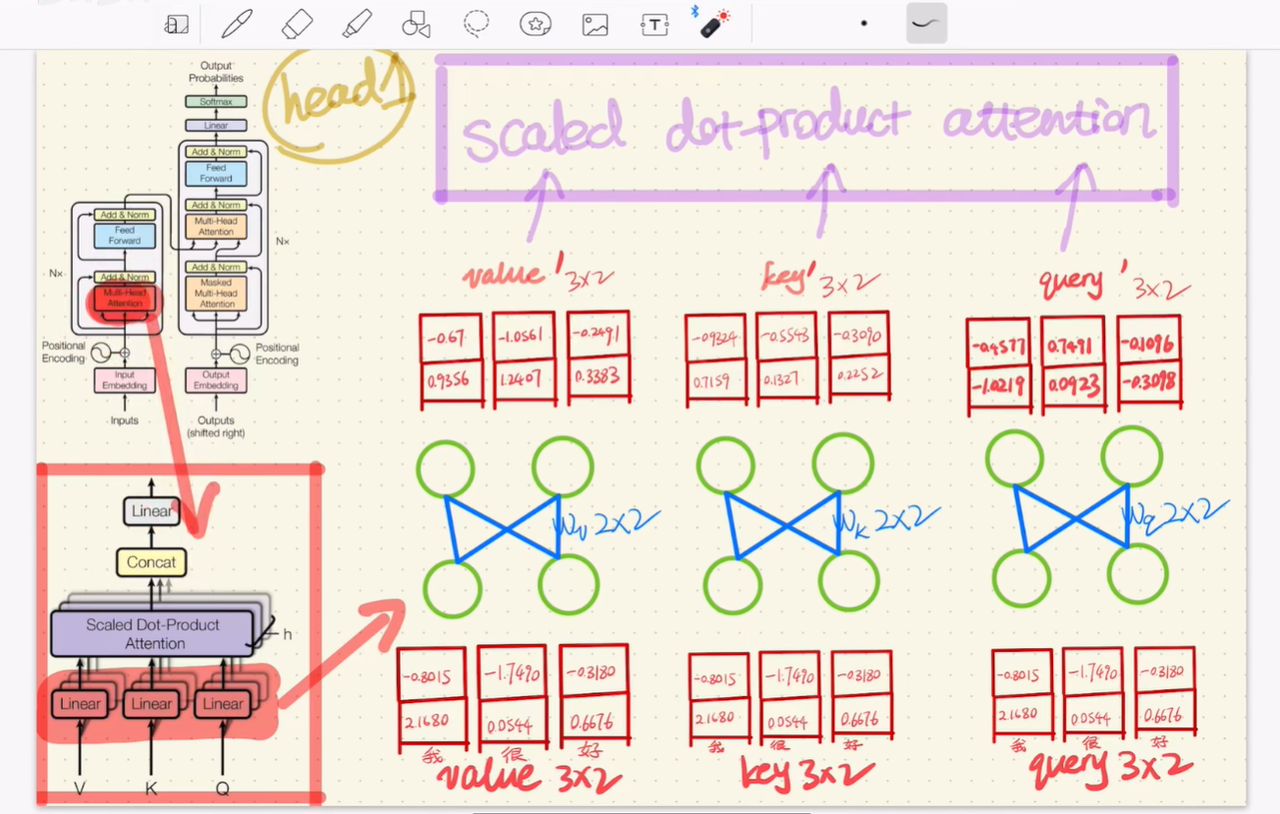
上图中的 Linear(线性变换) 即为缩放点积注意力中描述的 W_q、W_k、W_v 权重矩阵。经过变换后得到 Q、K、V 向量,也就是图中的 query'、key'、value',这三个变量直接参与缩放点积注意力的计算。
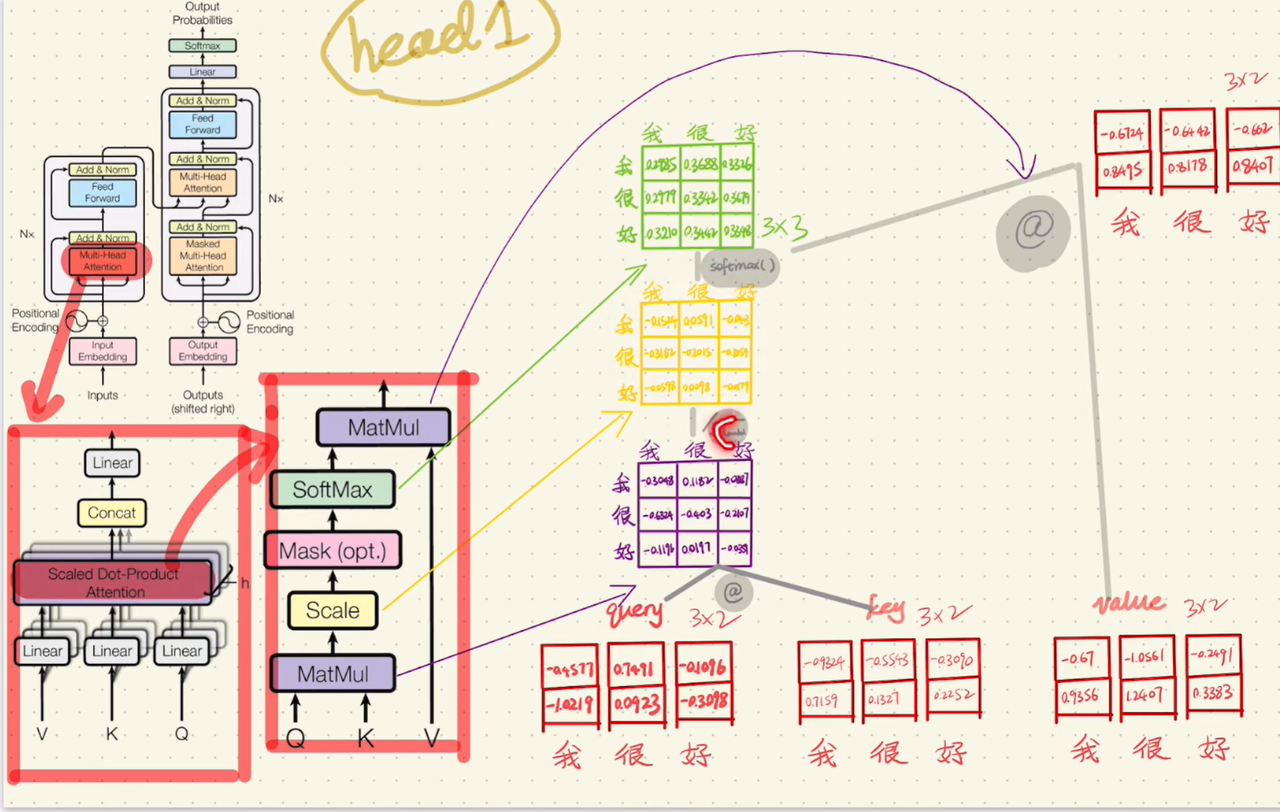
上图描述了 query' 与 key' 的转置矩阵乘法、Scale(缩放)、Softmax 归一化、与 V 的矩阵乘法,这些步骤在上文介绍缩放点积注意力时已经详细说明。
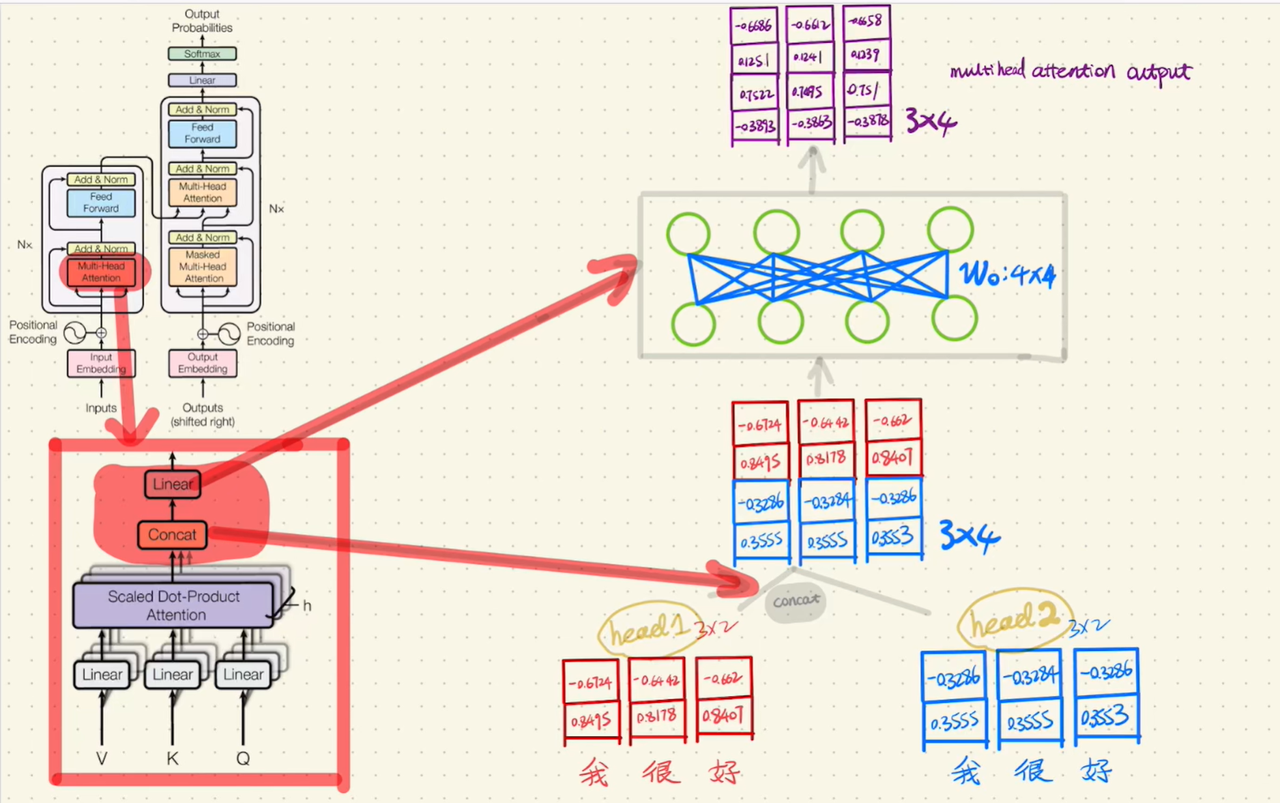
多个头分别计算完注意力后,将各头的输出进行拼接(Concat),再通过一个全连接层(Linear) 处理多个头之间的注意力信息,最终输出与输入维度相同的结果。
# 4.3 前馈神经网络(Feed-Forward Network)
多头自注意力让每个词元"看到"了其他词元,但这只是信息的聚合。接下来需要对聚合后的信息进行深度加工,这就是前馈神经网络(FFN)的作用。
# 4.3.1 结构
FFN 的结构很简单:先放大,再缩小。
FFN(x) = W_2 · ReLU(W_1 · x + b_1) + b_2
- W_1(第一层):将维度从 d_model 扩展到 d_ff(通常是 4 倍),把信息映射到更高维的空间
- ReLU(激活函数):引入非线性,让网络能学习复杂的模式
- W_2(第二层):将维度从 d_ff 压缩回 d_model,提取关键特征
# 4.3.2 作用
- 引入非线性:注意力机制本质是加权平均(线性操作),FFN 加入非线性变换,让模型能表达更复杂的关系
- 逐位置独立计算:FFN 对序列中每个位置独立应用相同的变换,不涉及位置间的交互
# 4.4 残差连接(Residual Connection)
观察架构图,每个子层后面都有一个 Add & Norm。这里的 Add 就是残差连接——一个看似简单却极其重要的设计。
# 4.4.1 前置概念
损失函数:衡量模型预测值与真实值的差距。训练的目标就是不断调整参数,让这个差距越来越小。
梯度:告诉模型"往哪个方向调整参数,损失下降最快"。
梯度消失 / 爆炸:
神经网络通过反向传播计算梯度,梯度需要逐层往回传:
- 如果每层梯度 < 1,连乘后趋近于 0 → 梯度消失,前面的层学不动
- 如果每层梯度 > 1,连乘后爆炸式增长 → 梯度爆炸,训练崩溃
退化问题:
退化问题是指当网络层数加深时,训练误差不降反升,模型性能出现下降。这种现象并非由于过拟合导致,而是因为过深的网络在当前优化器下难以找到理想的解——即使从理论上讲,一个更深的网络可以通过学恒等映射至少不比浅层网络差,但实际训练中却难以学到这种恒等映射,从而出现训练精度的“退化”。
# 4.4.2 残差连接的原理
残差连接的思路很直接:既然直接学恒等映射很难,那就把恒等映射直接加进去。
Output = LayerNorm(X + SubLayer(X))
简单说:输出 = 原始输入 + 子层学到的变化
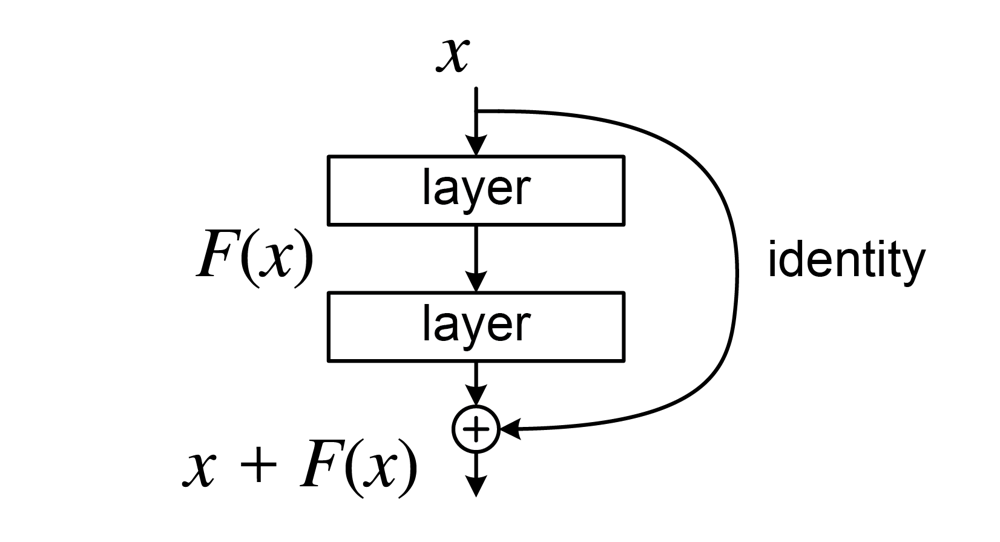
残差连接有效的原因
- 缓解梯度消失:反向传播时,梯度可通过恒等映射路径直接传递至前层,避免因链式法则导致的梯度衰减
- 降低优化难度:网络只需学习输入与目标输出之间的残差(差异),而非完整的映射函数
- 保证网络深度收益:当子层输出趋近于零时,整体输出退化为恒等映射,确保深层网络性能不低于浅层网络
# 4.4.3 层归一化(Layer Normalization)
Add & Norm 中的 Norm 指的是层归一化。它对每个样本的特征维度进行归一化,使数据分布更稳定。
为什么需要归一化?
神经网络在训练过程中,每一层的输入分布会随着参数更新不断变化(称为内部协变量偏移)。归一化可以:
- 稳定训练:将数据拉回到均值为 0、方差为 1 的标准分布,避免数值过大或过小
- 加速收敛:稳定的分布让梯度更平滑,模型更容易优化
- 减少对初始化的敏感性:即使初始参数不理想,归一化也能让训练正常进行
# 4.5 仅编码器架构(Encoder-Only)
仅编码器架构去掉了解码器部分,只保留编码器,专注于理解和表示输入文本。
# 4.5.1 代表模型
- BERT(Bidirectional Encoder Representations from Transformers)
- RoBERTa(更强的 BERT 变体)
- ALBERT(轻量化 BERT)
- DistilBERT(蒸馏版 BERT)
# 4.5.2 核心特点
双向注意力
与解码器的单向(因果)注意力不同,编码器使用双向注意力——每个词元可以同时关注左边和右边的所有词元。
解码器(单向):预测 "爱" 时,只能看到 "我"
编码器(双向):理解 "爱" 时,可以同时看到 "我" 和 "你"
2
这种双向理解能力让编码器更适合理解类任务,而非生成类任务。
预训练任务
BERT 使用两种预训练任务:
- 掩码语言模型(MLM):随机遮盖 15% 的词元,让模型预测被遮盖的词
- 下一句预测(NSP):判断两个句子是否连续
# 4.5.3 典型应用
| 任务类型 | 示例 |
|---|---|
| 文本分类 | 情感分析、垃圾邮件检测 |
| 命名实体识别 | 识别人名、地名、机构名 |
| 语义相似度 | 判断两句话是否表达相同意思 |
# 4.5.4 与仅解码器架构的对比
| 特性 | 仅编码器(BERT) | 仅解码器(GPT) |
|---|---|---|
| 注意力方向 | 双向 | 单向(因果) |
| 核心能力 | 理解 | 生成 |
| 典型任务 | 分类、抽取 | 文本生成、对话 |
| 输出形式 | 向量表示 | 逐词生成 |
