 5.解码器
5.解码器
# 5.1 解码器的结构

上图为 Transformer 整体架构,左侧为编码器(Encoder),右侧为解码器(Decoder)。
解码器负责根据编码器的输出,逐步生成目标序列。与编码器类似的,解码器同样由多个解码器层(Decoder Layer)堆叠而成,每个解码器层包含三个子层:
- 掩码多头自注意力(Masked Multi-Head Attention):让每个词元只能"看到"自己及之前的词元,防止信息泄露
- 多头注意力(Multi-Head Attention):也称为交叉注意力(Cross-Attention),让解码器关注编码器的输出,建立源序列与目标序列之间的联系。注意图中该模块有两个箭头从编码器输入,这正是它与自注意力的区别
- 前馈神经网络(Feed Forward):与编码器相同,对每个位置进行非线性变换
与编码器相比,解码器多了一个交叉注意力层,并且自注意力需要使用掩码机制。
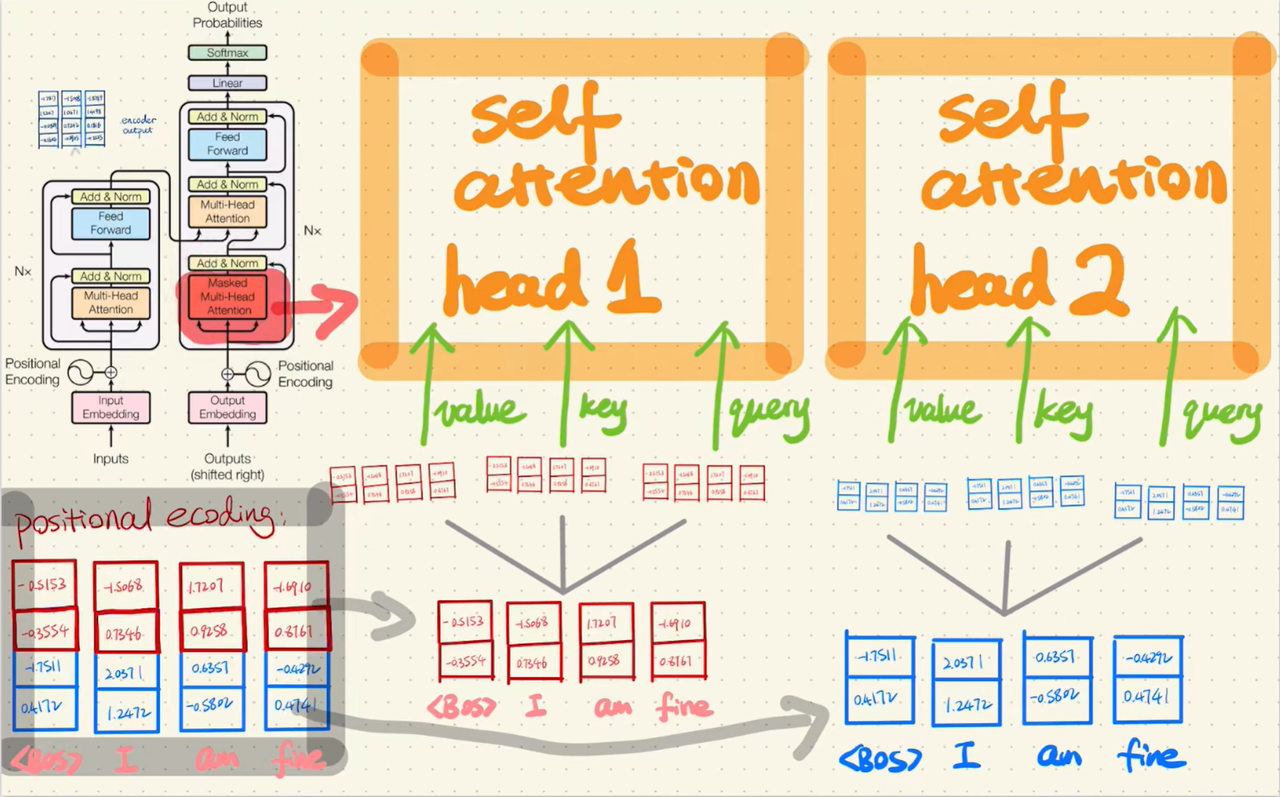
# 5.2 掩码自注意力(Masked Self-Attention)
# 5.2.1 为什么需要掩码?
解码器的核心任务是自回归生成,根据已生成的词预测下一个词。这意味着在预测第 i 个词时,模型只能看到前 i-1 个词,不能"偷看"后面的内容。
# 5.2.2 掩码的实现
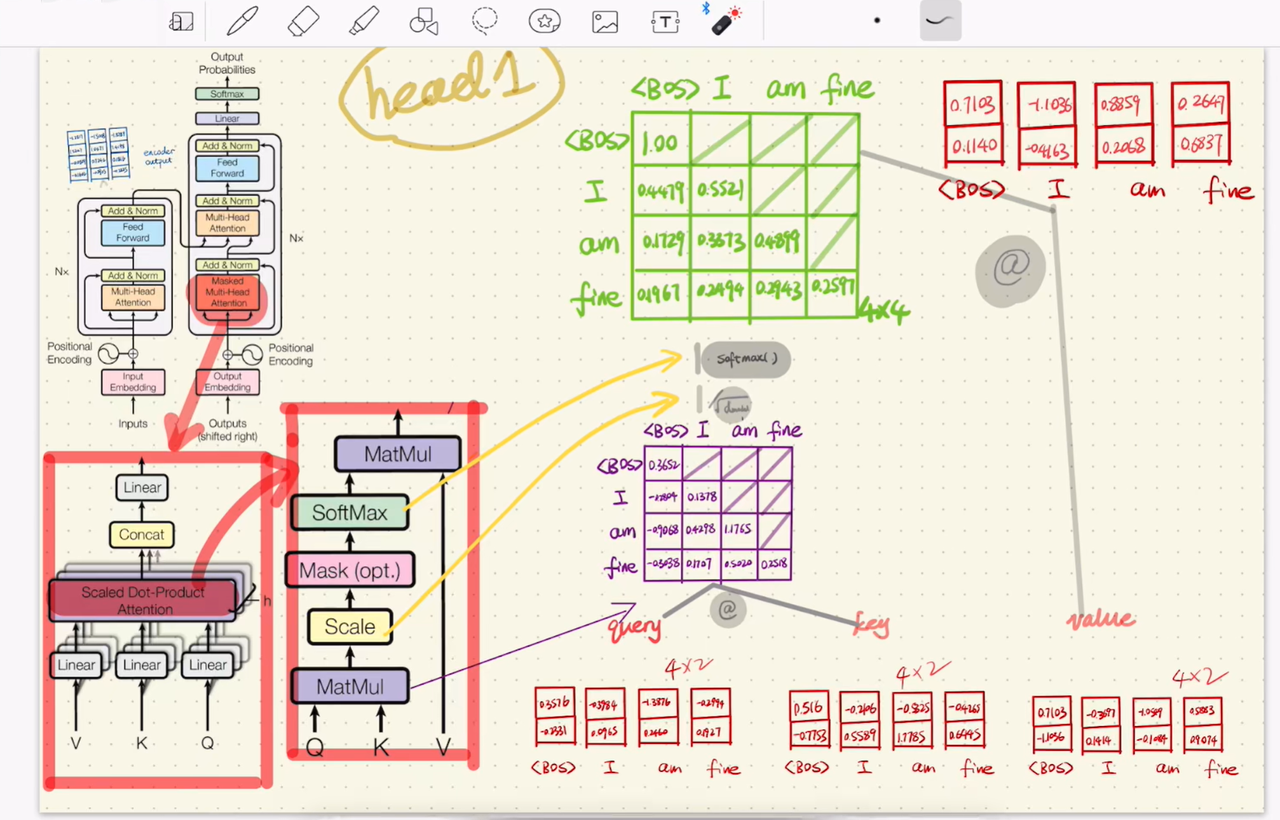
掩码自注意力在计算注意力分数时,通过一个上三角掩码矩阵将未来位置的分数设为负无穷:
Masked-Attention(Q, K, V) = softmax((QK^T / √d_k) + Mask) · V
掩码矩阵的结构如下(以序列长度 4 为例):
Mask = [[ 0, -∞, -∞, -∞ ],
[ 0, 0, -∞, -∞ ],
[ 0, 0, 0, -∞ ],
[ 0, 0, 0, 0 ]]
2
3
4
- 0:表示该位置可以被关注
- -∞:表示该位置被屏蔽,经过 Softmax 后权重趋近于 0
这样,每个位置只能关注自己及之前的位置,Mask Multi-Head Self-Attention除了掩码机制以外和多头自注意力机制一致,经过点积、缩放、掩码、Softmax和V矩阵乘法以及残差连接等得到输出,手推如下图所示:
# 5.2.3 训练与推理的区别
训练和推理阶段,解码器的工作方式有本质不同。
训练阶段(Teacher Forcing)
训练时,我们已经知道完整的目标序列(标准答案)。以翻译 "I love you" → "我爱你" 为例:
输入解码器:<BOS> 我 爱 你
目标输出: 我 爱 你 <EOS>
2
关键点:
- 整个目标序列一次性输入:
<BOS> 我 爱 你同时进入解码器 - 掩码保证公平:虽然"你"已经在输入中,但预测"爱"时,掩码会屏蔽"你"的信息
- 并行计算:所有位置的预测可以同时进行,大幅加速训练
这种用标准答案作为输入的方式叫做 Teacher Forcing(教师强制),就像老师在旁边提示正确答案,让模型更快学会。
推理阶段(自回归生成)
推理时,我们不知道目标序列,必须逐词生成:
第1步:输入 <BOS> → 预测出 "我"
第2步:输入 <BOS> 我 → 预测出 "爱"
第3步:输入 <BOS> 我 爱 → 预测出 "你"
第4步:输入 <BOS> 我 爱 你 → 预测出 <EOS>,结束
2
3
4
关键点:
- 逐词生成:每次只预测一个词,将结果追加到输入,再预测下一个
- 无法并行:必须等上一个词生成后才能预测下一个
- 终止条件:遇到结束符
<EOS>或达到最大长度时停止
# 5.3 多头注意力(Multi-Head Attention)
解码器中的多头注意力与编码器的多头自注意力结构相似,计算过程同样经过点积、缩放、Softmax、与 V 矩阵乘法以及残差连接。
唯一的区别在于 Q、K、V 的来源不同:
| 组件 | 编码器(自注意力) | 解码器(交叉注意力) |
|---|---|---|
| Q | 同一个输入 | Masked Multi-Head Attention 的输出 |
| K | 同一个输入 | 编码器的输出 |
| V | 同一个输入 | 编码器的输出 |
编码器自注意力:Q = X · W_q, K = X · W_k, V = X · W_v (Q、K、V 都由同一个 X 变换得到)
解码器交叉注意力:Q = M · W_q, K = E · W_k, V = E · W_v (Q 来自解码器,K、V 来自编码器)
2
其中 X 是编码器的输入(词嵌入 + 位置编码),M 是 Masked Multi-Head Attention 的输出,E 是编码器的最终输出。
这种设计让解码器能够"询问"编码器:当前要生成的词应该关注源序列的哪些部分?
交叉注意力同样经过点积、缩放、Softmax 和与 V 矩阵乘法,最终通过残差连接得到输出。注意:交叉注意力不需要掩码,因为编码器的输出是完整的,解码器可以关注源序列的任意位置。
# 5.4 解码器的完整流程
将上述组件整合,解码器的完整工作流程如下:
# 5.4.1 输入处理
- 目标序列嵌入:将目标词元转换为向量表示
- 位置编码:添加位置信息(与编码器使用相同的位置编码方式)
- 右移(Right Shift):在序列开头添加起始符
<BOS>,让模型知道从哪里开始生成
# 5.4.2 解码器层处理
每个解码器层依次执行:
1. 掩码多头自注意力
→ 关注已生成的词元,捕捉目标序列内部的依赖关系
→ 残差连接 + 层归一化
2. 交叉注意力
→ 关注编码器输出,获取源序列信息
→ 残差连接 + 层归一化
3. 前馈神经网络
→ 对每个位置进行非线性变换
→ 残差连接 + 层归一化
2
3
4
5
6
7
8
9
10
11
# 5.4.3 输出生成(Linear & Softmax)
解码器最后一层输出的是隐藏状态向量,维度为 d_model(如 512)。但我们最终需要的是"下一个词是什么",这就需要 Linear 和 Softmax 层来完成转换。
第一步:Linear(线性层)
线性层将隐藏状态从 d_model 维投影到词表大小 vocab_size(如 30000):
logits = hidden_state · W + b # 输出维度:[vocab_size]
输出的 logits 是一个长度为词表大小的向量,每个位置对应词表中一个词的"分数"。分数越高,表示模型越倾向于选择这个词。
第二步:Softmax(归一化)
Softmax 将分数转换为概率分布(所有值在 0~1 之间,总和为 1):
probabilities = softmax(logits)
例如,假设词表只有 5 个词:
词表: ["我", "爱", "你", "他", "她"]
logits: [2.1, 5.3, 1.2, 0.5, 0.8]
softmax: [0.03, 0.82, 0.01, 0.07, 0.07]
↑
概率最高,选择 "爱"
2
3
4
5
第三步:选择输出词
根据概率分布选择最终输出:
- 贪婪解码(Greedy):直接选概率最高的词
- 采样(Sampling):按概率随机抽样,增加多样性
- Top-k / Top-p:只在概率最高的 k 个词或累积概率达到 p 的词中采样
训练与推理的区别
Linear & Softmax 的执行方式在训练和推理阶段有所不同:
- 训练阶段:每个位置都执行,一次前向传播计算整个序列的 loss
输入: <BOS> 我 爱 你
↓ ↓ ↓ ↓
Linear: [L1] [L2] [L3] [L4] ← 每个位置都计算 logits
↓ ↓ ↓ ↓
目标: 我 爱 你 <EOS> ← 每个位置都有对应的标签,计算交叉熵损失
2
3
4
5
- 推理阶段:只对最后一个位置执行,因为只需预测下一个词
第1步:输入 <BOS> → 只取最后位置 → Linear & Softmax → "我"
第2步:输入 <BOS> 我 → 只取最后位置 → Linear & Softmax → "爱"
第3步:输入 <BOS> 我 爱 → 只取最后位置 → Linear & Softmax → "你"
2
3
# 5.5 解码器与编码器的对比
| 特性 | 编码器 | 解码器 |
|---|---|---|
| 子层数量 | 2 个 | 3 个 |
| 自注意力 | 无掩码(双向) | 有掩码(单向/因果) |
| 交叉注意力 | 无 | 有(连接编码器) |
| 信息流向 | 双向(可看全部) | 单向(只看过去) |
| 主要任务 | 理解/编码输入 | 生成/解码输出 |
# 5.6 仅解码器架构(Decoder-Only)
现代大语言模型(如 GPT、LLaMA、Claude)采用仅解码器架构,去掉了编码器和交叉注意力层,只保留掩码自注意力和前馈神经网络。
# 5.6.1 为什么只用解码器?
- 统一的生成范式:所有任务都可以转化为"给定上文,预测下文"
- 更大的规模:相同参数量下,单一架构可以堆叠更多层
- 涌现能力:足够大的自回归模型展现出惊人的少样本学习能力
# 5.6.2 与完整 Transformer 的区别
- 没有编码器,输入直接进入解码器
- 没有交叉注意力,只有掩码自注意力
- 输入和输出使用同一个序列空间(如对话中的 prompt + response)
完整 Transformer: Encoder(源序列) → Decoder(目标序列) → 输出
Decoder-Only: Decoder(上文 + 已生成部分) → 输出下一个词
2
这种简化不仅降低了模型复杂度,还让模型能够更灵活地处理各种任务,成为当今 LLM 的主流架构。
