 3.全量微调
3.全量微调
全量微调(Full Fine-tuning)是最直接的微调方式,更新模型的所有参数,让模型完全适应新任务。
# 3.1 全量微调原理
# 3.1.1 基本概念
全量微调在预训练模型的基础上,使用特定任务的数据继续训练,更新模型的所有参数。
预训练模型参数:θ_pretrain
微调后模型参数:θ_finetuned = θ_pretrain + Δθ
其中 Δθ 是通过梯度下降在新数据上学习到的参数更新
1
2
3
4
2
3
4
# 3.1.2 训练过程
- 前向传播:输入数据通过模型,计算预测输出
- 计算损失:比较预测输出与真实标签,计算损失函数
- 反向传播:计算损失对所有参数的梯度
- 参数更新:使用优化器更新所有参数
# 3.1.3 损失函数
对于语言模型,通常使用交叉熵损失(Cross-Entropy Loss):
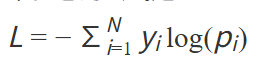
# 3.2 显存需求分析
# 3.2.1 显存组成
| 组成部分 | 占用比例 | 说明 |
|---|---|---|
| 模型参数 | ~20% | 模型权重本身 |
| 梯度 | ~20% | 每个参数对应一个梯度 |
| 优化器状态 | ~40% | Adam 需要存储一阶和二阶动量 |
| 激活值 | ~20% | 前向传播的中间结果 |
# 3.2.2 显存估算
以 FP32 精度为例:
模型参数:4B × 参数量
梯度:4B × 参数量
Adam 优化器状态:8B × 参数量
总计 ≈ 16B × 参数量(不含激活值)
1
2
3
4
5
2
3
4
5
| 模型规模 | FP32 显存需求 | FP16 显存需求 |
|---|---|---|
| 7B | ~112GB | ~56GB |
| 13B | ~208GB | ~104GB |
| 70B | ~1120GB | ~560GB |
# 3.2.3 混合精度训练
使用 FP16/BF16 可以显著降低显存占用,同时保持训练精度。BF16 数值范围更大,训练更稳定。
# 3.3 关键超参数
# 3.3.1 学习率
学习率是最重要的超参数,决定了参数更新的步长。
| 阶段 | 学习率范围 |
|---|---|
| 预训练 | 1e-4 ~ 1e-3 |
| 微调 | 1e-5 ~ 5e-5 |
微调使用更小的学习率,避免破坏预训练知识。
学习率调度策略:
| 策略 | 特点 |
|---|---|
| linear | 线性衰减到 0 |
| cosine | 余弦曲线衰减,更平滑 |
| constant_with_warmup | 预热后保持不变 |
# 3.3.2 批次大小
批次大小影响训练稳定性和收敛速度。
- 有效批次大小 = 单卡批次 × 梯度累积步数 × GPU 数量
- 显存不足时,可通过梯度累积模拟大批次效果
# 3.3.3 训练轮数
- 通常 1-5 轮
- 轮数过多可能导致过拟合
- 建议配合早停策略
# 3.3.4 权重衰减
权重衰减(Weight Decay)是一种正则化技术,常用值 0.01 ~ 0.1。
# 3.4 显存优化技术
# 3.4.1 梯度检查点
梯度检查点(Gradient Checkpointing)通过重新计算激活值来节省显存。
- 原理:前向传播时不保存所有激活值,反向传播时重新计算
- 效果:显存减少约 30-50%,训练时间增加约 20%
# 3.4.2 DeepSpeed ZeRO
ZeRO(Zero Redundancy Optimizer)在多 GPU 间分片存储:
| ZeRO Stage | 分片内容 | 显存节省 |
|---|---|---|
| Stage 1 | 优化器状态 | ~4x |
| Stage 2 | 优化器状态 + 梯度 | ~8x |
| Stage 3 | 优化器状态 + 梯度 + 参数 | ~N x |
# 3.4.3 其他优化
- CPU Offload:将部分数据卸载到 CPU 内存
- FSDP:PyTorch 原生的全分片数据并行
# 3.5 优缺点与适用场景
# 3.5.1 优点
- 效果最好:所有参数都参与学习,模型能充分适应新任务
- 实现简单:直接在预训练模型上继续训练
- 灵活性高:可以学习任意复杂的任务
# 3.5.2 缺点
- 资源需求高:需要大量 GPU 显存
- 存储成本高:每个任务需要保存完整的模型副本
- 灾难性遗忘:可能丢失预训练知识
- 过拟合风险:数据量少时容易过拟合
# 3.5.3 适用场景
| 场景 | 是否推荐 |
|---|---|
| 数据量充足(>10K) | ✅ 推荐 |
| 计算资源充足 | ✅ 推荐 |
| 需要最佳效果 | ✅ 推荐 |
| 数据量少(<1K) | ❌ 建议用 PEFT |
| 资源有限 | ❌ 建议用 PEFT |
| 需要多任务切换 | ❌ 建议用 PEFT |
# 3.6 常见问题
# 3.6.1 训练不收敛
- 调整学习率(尝试更小的值)
- 检查数据格式和质量
- 使用梯度裁剪防止梯度爆炸
# 3.6.2 过拟合
- 减少训练轮数
- 增加正则化(weight_decay)
- 使用早停策略
- 增加训练数据
# 3.6.3 显存不足
优先级从高到低:
- 减小批次大小,增加梯度累积
- 启用混合精度训练
- 启用梯度检查点
- 使用 DeepSpeed ZeRO
- 考虑使用 LoRA 等 PEFT 方法
编辑 (opens new window)
上次更新: 2025/12/19, 15:17:48
