 1.Transformer概述
1.Transformer概述
Transformer是2017年由Google团队在论文《Attention Is All You Need》中提出的一种革命性的深度学习架构。它彻底改变了自然语言处理(NLP)领域,并成为当今大语言模型(LLM)的核心基础。
# 1.1 诞生背景
# 1.1.1 传统序列模型的局限
在Transformer出现之前,处理序列数据主要依赖循环神经网络(RNN)和长短时记忆网络(LSTM):
- 顺序计算限制:RNN/LSTM必须按时间步顺序处理,无法并行计算,训练效率低
- 长距离依赖问题:虽然LSTM改进了梯度消失问题,但对于超长序列仍难以捕捉远距离依赖关系
- 计算复杂度高:序列长度增加时,计算时间线性增长
# 1.1.2 注意力机制
注意力机制(Attention Mechanism)最初作为RNN的辅助模块,用于解决机器翻译中的长句子问题。Transformer的创新在于:完全抛弃循环结构,仅用注意力机制构建整个模型。
# 1.2 核心架构
Transformer采用 编码器-解码器 (Encoder-Decoder)架构:
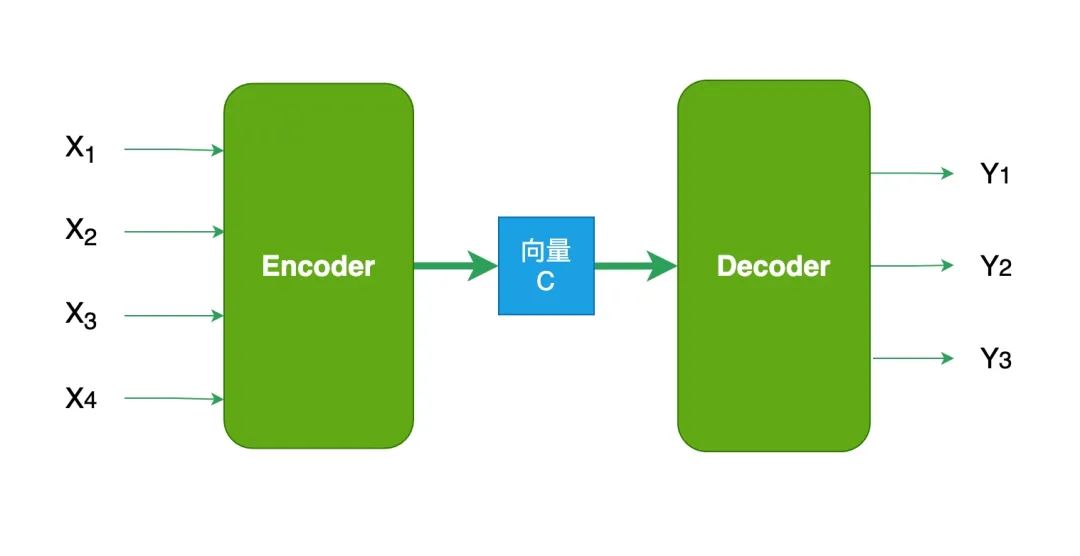
- 编码器(Encoder):负责理解输入,将文本转换为包含上下文信息的向量表示
- 解码器(Decoder):负责生成输出,根据编码器的理解逐步产生结果
两者的核心都是 注意力机制——让模型在处理每个词时,能够"看到"并关注句子中的其他相关词。
# 1.3 Transformer的优势
| 特性 | 传统RNN/LSTM | Transformer |
|---|---|---|
| 并行计算 | 不支持(顺序依赖) | 完全支持 |
| 长距离依赖 | 困难(信息会逐渐衰减) | 轻松捕捉(任意两词可直接交互) |
| 训练效率 | 较慢 | 显著更快 |
| 可解释性 | 较差 | 注意力权重可视化 |
# 1.4 Transformer变体
# 1.4.1 仅编码器模型(Encoder-Only)
- 代表:BERT、RoBERTa
- 特点:双向注意力,适合理解任务
- 应用:文本分类、命名实体识别、问答
# 1.4.2 仅解码器模型(Decoder-Only)
- 代表:GPT系列、LLaMA、Claude
- 特点:单向(因果)注意力,自回归生成
- 应用:文本生成、对话系统、代码生成
# 1.4.3 编码器-解码器模型(Encoder-Decoder)
- 代表:T5、BART
- 特点:保留完整架构
- 应用:机器翻译、文本摘要、问答生成
编辑 (opens new window)
上次更新: 2025/12/19, 15:17:48
