 3. Advanced RAG
3. Advanced RAG
Advanced RAG (高级检索增强生成)并不是一个具有标准定义的术语,它泛指在基础RAG架构之上,为应对特定挑战而引入一系列更复杂、精细且智能的技术与策略所形成的优化RAG集合体。本文将遵循RAG的工作流程,详细剖析这些优化策略。下图(源自 huggingface (opens new window))以蓝色标注了RAG系统的各项潜在优化方向。
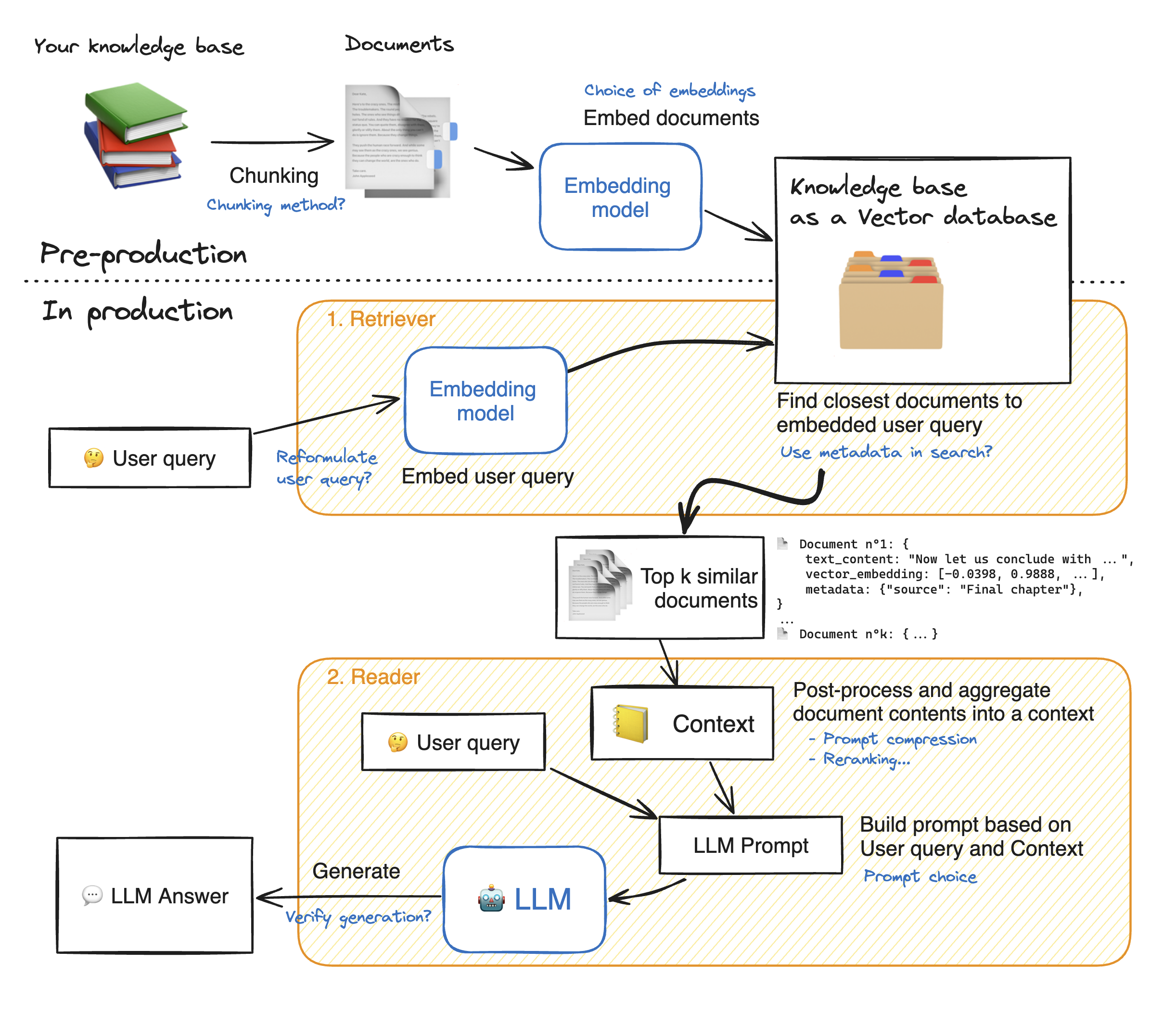
# 3.1 知识库构建阶段
知识库构建阶段是整个RAG系统的基石,其优化策略直接影响到后续的检索效果。原始数据通常是非结构化的,需要经过一系列精细处理才能转化为可供模型高效检索的格式。高级RAG在此阶段的优化主要集中在 分块优化 (Chunking Optimization)、元数据丰富 (Metadata Enrichment) 和 索引结构优化 (Indexing Optimization) 三个方面。
# 3.1.1 分块优化 (Chunk Optimization)
# 3.1.1.1 重叠分块
为了解决信息跨块分布的问题,我们可以采用重叠块策略,确保重要信息不会因为分块边界而丢失。
def create_overlapping_chunks(text, chunk_size=512, overlap_size=50):
"""
创建重叠的文本块
"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
# 下一个块的起始位置重叠
start = start + chunk_size - overlap_size
if start >= len(text):
break
return chunks
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.1.1.2 递归分割
对于多级文档,我们可以使用 Langchain 提供的 RecursiveCharacterTextSplitter。RecursiveCharacterTextSplitter 采用递归分割策略,按照预定义的分隔符优先级顺序进行文档分割,确保在保持语义完整性的同时控制分块大小,以下是一个简单的示例:
pip install langchain
from langchain.text_splitter import RecursiveCharacterTextSplitter
default_separators = [
"\n## ", # 二级标题
"\n### ", # 三级标题
"\n#### ", # 四级标题
"\n\n", # 段落分隔
"\n", # 行分隔
" ", # 空格
"" # 字符级
]
def create_recursive_splitter(chunk_size=1000, chunk_overlap=200):
"""
创建递归字符文本分割器
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=default_separators,
length_function=len,
)
return text_splitter
text_splitter = create_recursive_splitter()
chunks = text_splitter.split_text(document_text)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 3.1.1.3 语义分割
在实际应用中,由于预定义规则很死板,基于规则的分块方法很容易导致诸如检索上下文不完整或分块过大含有噪声等问题。因此最优雅的方法是基于语义进行分块。语义分块的宗旨是确保每个分块尽可能包含语义上独立的信息。
# 3.1.1.3.1 SemanticChunker语义分割
LangChain 提供了 SemanticChunker 工具来实现语义分块, 以下是使用示例:
pip install langchain-experimental langchain-openai
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
# 初始化嵌入模型
embeddings = OpenAIEmbeddings()
# 创建语义分块器
semantic_chunker = SemanticChunker(
embeddings=embeddings,
buffer_size=3,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=70,
)
# 执行语义分块
chunks = semantic_chunker.split_text(document_text)
# 或者直接分割文档
documents = semantic_chunker.split_documents(doc_list)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 3.1.1.3.2 SemanticChunker 类的定义
class SemanticChunker(
embeddings: Embeddings, # 向量模型,用于生成句子Embedding
buffer_size: int = 1, # 向前向后取 buffer_size 个句子一起 Embedding,以减少噪声
add_start_index: bool = False, # 是否在元数据中添加切分块在原文中的起始字符位置
breakpoint_threshold_type: BreakpointThresholdType = "percentile", # 切分点计算方法,默认为“分位法”
breakpoint_threshold_amount: float | None = None, # 切分点计算阈值,具体含义取决于 breakpoint_threshold_type
number_of_chunks: int | None = None, # 期望切分后的文档块数量,用于反向推导阈值
sentence_split_regex: str = r"(?<=[.?!])\s+", # 句子切分规则,默认为英文标点符号
min_chunk_size: int | None = None # 最小文档块大小,用于合并过小的文档块
)
2
3
4
5
6
7
8
9
10
# 3.1.1.3.2 SemanticChunker 基本原理
- 句子切分
文档首先需要被切分成独立的句子,SemanticChunker 通过 sentence_split_regex 参数来设置句子切分规则。默认值为
r"(?<=[.?!])\s+",该切分方式适用于英文文档,它以英文的句号、问号、感叹号后跟空白字符作为分隔符。对于中文文档,我们需要将正则表达式替换为能够有效切分中文句子的规则,例如r"(?<=[。?!\n])",即以中文的句号、问号、感叹号以及换行符作为切分点。
import re
def _get_single_sentences_list(self, text: str) -> List[str]:
return re.split(self.sentence_split_regex, text)
2
3
4
- 句子组合与向量化
在获得独立的句子列表后,SemanticChunker 会根据 buffer_size 参数将相邻句子组合成句子组。这种设计的核心目的是通过引入上下文信息来降低单句向量化时的噪声干扰,提升语义表征的准确性。
def combine_sentences(sentences: List[dict], buffer_size: int = 1) -> List[dict]:
for i in range(len(sentences)):
combined_sentence = ""
# 添加当前句子之前 buffer_size 个句子
for j in range(i - buffer_size, i):
if j >= 0:
combined_sentence += sentences[j]["sentence"] + " "
# 添加当前句子
combined_sentence += sentences[i]["sentence"]
# 添加当前句子之后 buffer_size 个句子
for j in range(i + 1, i + 1 + buffer_size):
if j < len(sentences):
combined_sentence += " " + sentences[j]["sentence"]
sentences[i]["combined_sentence"] = combined_sentence
return sentences
2
3
4
5
6
7
8
9
10
11
12
13
14
15
随后,利用嵌入模型将每个句子组转换为高维语义向量,这些向量能够在语义空间中精确表征文本的深层含义。
def _calculate_sentence_distances(self, single_sentences_list: List[str]) -> Tuple[List[float], List[dict]]:
_sentences = [
{"sentence": x, "index": i} for i, x in enumerate(single_sentences_list)
]
sentences = combine_sentences(_sentences, self.buffer_size)
embeddings = self.embeddings.embed_documents(
[x["combined_sentence"] for x in sentences]
)
for i, sentence in enumerate(sentences):
sentence["combined_sentence_embedding"] = embeddings[i]
return calculate_cosine_distances(sentences)
2
3
4
5
6
7
8
9
10
11
- 相似度计算与分割点识别
SemanticChunker 通过计算相邻句子组向量之间的余弦距离来量化语义变化程度。当相邻句子组的语义距离超过预设阈值时,说明话题或语义发生了显著转换,此处即被标记为潜在的分割点。
from langchain_community.utils.math import cosine_similarity
def calculate_cosine_distances(sentences: List[dict]) -> Tuple[List[float], List[dict]]:
distances = []
for i in range(len(sentences) - 1):
embedding_current = sentences[i]["combined_sentence_embedding"]
embedding_next = sentences[i + 1]["combined_sentence_embedding"]
similarity = cosine_similarity([embedding_current], [embedding_next])[0][0]
distance = 1 - similarity
distances.append(distance)
sentences[i]["distance_to_next"] = distance
return distances, sentences
2
3
4
5
6
7
8
9
10
11
12
13
距离阈值的确定方式由 breakpoint_threshold_type 参数控制,支持三种策略:
- 百分位法 (percentile):基于距离分布的统计特性,选取第 N 百分位数作为阈值。例如设置
breakpoint_threshold_amount=70,则将所有距离值的第70百分位数作为切分阈值,超过该值的位置即为分割点。也可以通过 number_of_chunks 参数指定期望的文档块数量,系统会反向推导出相应的分位数。
import numpy as np
def _calculate_breakpoint_threshold(self, distances: List[float]) -> Tuple[float, List[float]]:
# 第一种方式:指定分位数
return cast(
float,
np.percentile(distances, self.breakpoint_threshold_amount),
), distances
2
3
4
5
6
7
- 标准差法 (standard_deviation):将所有余弦距离的平均值加上 X 倍的标准差作为阈值。该方法适用于数据呈正态分布的情况,breakpoint_threshold_amount 默认为 3。
import numpy as np
def _calculate_breakpoint_threshold(self, distances: List[float]) -> Tuple[float, List[float]]:
return cast(
float,
np.mean(distances) +
self.breakpoint_threshold_amount * np.std(distances),),
distances
2
3
4
5
6
7
- 四分位距法 (interquartile):基于四分位距(IQR)检测离群值,阈值计算公式为
Q3 + k * IQR,其中 Q3 为第三四分位数,IQR = Q3 - Q1。
import numpy as np
def _calculate_breakpoint_threshold(self, distances: List[float]) -> Tuple[float, List[dict]]:
q1, q3 = np.percentile(distances, [25, 75])
iqr = q3 - q1
return np.mean(distances) + \
self.breakpoint_threshold_amount * iqr, distances
2
3
4
5
6
- 梯度法(gradient): 首先计算所有余弦距离的变化梯度,然后将变化梯度的第 X 百分位数作为阈值。这种方法能够捕捉余弦距离变化最快的点,breakpoint_threshold_amount 默认为 95。
import numpy as np
def _calculate_breakpoint_threshold(self, distances: List[float]) -> Tuple[float, List[float]]:
distance_gradient = np.gradient(distances, range(0, len(distances)))
return cast(
float,
np.percentile(distance_gradient,
self.breakpoint_threshold_amount)),
distance_gradient
2
3
4
5
6
7
8
- 分块生成与后处理
识别出所有分割点后,SemanticChunker 将原文本按照这些分割点切分成多个语义完整的文本块。为了避免产生过小的碎片化分块,可以通过 min_chunk_size 参数设定最小块大小约束,将过小的分块与相邻块合并。
def split_text(self, text: str,) -> List[str]:
distances, sentences = self._calculate_sentence_distances(single_sentences_list)
breakpoint_distance_threshold, breakpoint_array = self._calculate_breakpoint_threshold(distances)
indices_above_thresh = [
i
for i, x in enumerate(breakpoint_array)
if x > breakpoint_distance_threshold
]
chunks = []
start_index = 0
for index in indices_above_thresh:
end_index = index
group = sentences[start_index : end_index + 1]
combined_text = " ".join([d["sentence"] for d in group])
if (
self.min_chunk_size is not None
and len(combined_text) < self.min_chunk_size
):
continue
chunks.append(combined_text)
start_index = index + 1
if start_index < len(sentences):
combined_text = " ".join([d["sentence"] for d in sentences[start_index:]])
chunks.append(combined_text)
return chunks
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
经过 SemanticChunker 切分后,虽然语义连贯性得到了提升,但切分出的文档块可能存在长度不均的问题。为了获得更好的检索效果,我们通常需要对切分后的文档块进行二次处理,比如二次切分较长的文档块,合并较短的文档块,添加标题等
# 3.1.2 元数据丰富 (Metadata Enrichment)
元数据丰富是指在文档分块过程中,为每个文本块添加额外的结构化信息,以便在检索阶段能够更精确地定位和过滤相关内容。合理的元数据设计不仅能够提升检索的准确性,还能显著增强RAG系统的可解释性和可控性。
# 3.1.2.1 基础元数据
基础元数据主要包括文档的基本属性信息,这些信息能够帮助我们追溯数据来源、定位文档位置等。常见的基础元数据字段包括:
| 元数据字段 | 说明 | 示例值 |
|---|---|---|
| chunk_id | 文本块唯一标识符 | uuid |
| document_id | 所属文档ID | uuid |
| source | 文档来源路径 | data/papers/rag_survey.pdf |
| chunk_index | 文本块在文档中的序号 | 0, 1, 2... |
| start_char | 在原文档中的起始字符位置 | 1024 |
| end_char | 在原文档中的结束字符位置 | 2048 |
| chunk_length | 文本块字符长度 | 1024 |
| created_at | 创建时间戳 | 2025-01-15T10:30:00 |
# 3.1.2.2 结构化元数据
对于具有层次结构的文档(如技术文档、学术论文等),提取并保存文档的结构信息至关重要。这些结构信息包括标题层级、章节归属等,能够帮助模型更好地理解文档的组织方式。例如:
| 元数据字段 | 说明 | 示例值 |
|---|---|---|
| section_level_1 | 一级标题(章) | 第三章 知识库构建 |
| section_level_2 | 二级标题(节) | 3.1 分块优化 |
| section_level_3 | 三级标题(小节) | 3.1.1 重叠分块 |
| page_number | 页码(PDF文档) | 15 |
| heading_hierarchy | 完整标题层级路径 | ["第三章", "3.1 分块优化", "3.1.1 重叠分块"] |
| document_type | 文档类型 | pdf, markdown, html |
| language | 文档语言 | zh-CN |
# 3.1.2.3 语义元数据
语义元数据通过自然语言处理技术提取文本的深层语义特征,包括实体、摘要等,这些信息能够辅助检索系统更准确地理解文本内容。
# 3.1.2.3.1 实体提取
使用Spacy可以快速提取文本中的命名实体(人名、地名、组织名、日期等),这些实体信息对于理解文本主题和内容分类非常有帮助。
pip install spacy
python -m spacy download zh_core_web_sm
2
import spacy
from typing import List, Dict
# 加载中文模型
nlp = spacy.load("zh_core_web_sm")
def extract_entities(text: str) -> Dict[str, List[str]]:
"""
使用 Spacy 提取命名实体
Returns:
按实体类型分类的实体字典
"""
doc = nlp(text)
entities = {}
for ent in doc.ents:
entity_type = ent.label_
entity_text = ent.text
if entity_type not in entities:
entities[entity_type] = []
# 去重
if entity_text not in entities[entity_type]:
entities[entity_type].append(entity_text)
return entities
def extract_entities_flat(text: str) -> List[str]:
"""
提取所有实体的扁平列表
"""
doc = nlp(text)
return list(set([ent.text for ent in doc.ents]))
# 使用示例
if __name__ == "__main__":
text = "OpenAI在2023年发布了GPT-4模型,引起了人工智能领域的广泛关注。"
entities = extract_entities(text)
print(entities)
# 结果: {'ORG': ['OpenAI'], 'DATE': ['2023年'], 'PRODUCT': ['GPT-4']}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
常见的实体类型包括:
| 实体类型 | 说明 | 示例 |
|---|---|---|
| PERSON | 人名 | 张三, Elon Musk |
| ORG | 组织机构名 | OpenAI, 清华大学 |
| GPE | 地理政治实体 | 北京, 美国 |
| DATE | 日期 | 2023年, 昨天 |
| PRODUCT | 产品名称 | GPT-4, iPhone |
| EVENT | 事件 | 世界杯, 奥运会 |
| LOC | 地点 | 长城, 太平洋 |
# 3.1.2.3.2 自动摘要生成
对于较长的文本块,我们可以使用大语言模型生成简洁的摘要,这些摘要可以作为元数据存储,在检索时提供额外的语义信息。
from openai import OpenAI
def generate_chunk_summary(text: str, max_length: int = 100) -> str:
"""
使用 LLM 生成文本块摘要
"""
client = OpenAI()
prompt = f"""请为以下文本生成一个简洁的摘要(不超过{max_length}字):
{text}
摘要:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": prompt}
],
max_tokens=150,
temperature=0.3
)
return response.choices[0].message.content.strip()
# 使用示例
for chunk in chunks:
if len(chunk.text) > 500: # 只为较长的文本块生成摘要
summary = generate_chunk_summary(chunk.text)
chunk.metadata['summary'] = summary
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 3.1.2.3.3 假设性问题生成
除了摘要,我们还可以为每个文本块生成该块能够回答的假设性问题。这种方法在检索时特别有效,因为用户的查询通常是问题形式,而假设性问题与实际问题的语义相似度往往高于原文与问题的相似度。
def generate_hypothetical_questions(text: str, num_questions: int = 3) -> List[str]:
"""
为文本块生成假设性问题
"""
client = OpenAI()
prompt = f"""基于以下文本内容,生成{num_questions}个该文本能够回答的问题。
每个问题独立一行,不要编号。
文本:
{text}
问题:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": prompt}
],
max_tokens=200,
temperature=0.5
)
questions = response.choices[0].message.content.strip().split('\n')
return [q.strip() for q in questions if q.strip()]
# 使用示例
for chunk in chunks:
hypothetical_questions = generate_hypothetical_questions(chunk.text)
chunk.metadata['hypothetical_questions'] = hypothetical_questions
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 3.1.2.4 元数据在检索中的应用
丰富的元数据不仅能够帮助我们更好地组织知识库,还能在检索阶段发挥重要作用。通过元数据过滤,我们可以在执行向量检索之前缩小搜索范围,提高检索效率和准确性。
# 3.1.2.4.1 基于元数据的过滤检索
from typing import List, Dict, Optional
class MetadataFilteredRetriever:
def __init__(self, vector_store):
self.vector_store = vector_store
def retrieve(
self,
query: str,
top_k: int = 5,
filters: Optional[Dict[str, Any]] = None
) -> List[Dict[str, Any]]:
"""
支持元数据过滤的检索
Args:
query: 查询文本
top_k: 返回结果数量
filters: 元数据过滤条件
例如: {
"document_id": "doc_123",
"section_level_1": "第三章",
"created_at": {"$gte": "2024-01-01"}
}
"""
# 构建检索参数
search_kwargs = {"k": top_k}
if filters:
search_kwargs["filter"] = filters
# 执行检索
results = self.vector_store.similarity_search(
query,
**search_kwargs
)
return results
# 使用示例:只检索特定文档的特定章节
retriever = MetadataFilteredRetriever(vector_store)
results = retriever.retrieve(
query="如何优化分块策略?",
top_k=5,
filters={
"document_id": "advanced_rag_guide",
"section_level_1": "知识库构建阶段"
}
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
通过系统化的元数据丰富策略,RAG系统不仅能够更精确地检索相关信息,还能为用户提供更丰富的上下文和更透明的信息来源,显著提升整体的可用性和可信度。
# 3.2 检索阶段
检索阶段是 RAG 系统的核心环节,其优化策略直接决定了最终生成结果的质量。高级 RAG 在此阶段的优化主要集中在 查询改写 (Query Rewriting)、检索策略优化 (Retrieval Strategy) 和 重排序 (Reranking) 三个方面。
# 3.2.1 查询改写 (Query Rewriting)
用户的原始查询往往存在表述模糊、信息不完整或与知识库语义不匹配等问题,直接使用原始查询进行检索可能导致召回率低下或结果不相关。查询改写通过对原始查询进行优化、扩展或转换,显著提升检索的准确性和召回率。
# 3.2.1.1 查询扩展 (Query Expansion)
查询扩展通过添加同义词、相关术语或上下文信息来丰富原始查询,扩大检索范围的同时保持语义相关性。
from openai import OpenAI
from typing import List
def expand_query(query: str, num_expansions: int = 3) -> List[str]:
"""
使用 LLM 扩展查询,生成多个语义相关的查询变体
"""
client = OpenAI()
prompt = f"""请为以下查询生成{num_expansions}个语义相关的查询变体。
每个变体应该:
1. 保持原始查询的核心意图
2. 使用不同的表述方式或同义词
3. 可能添加相关的上下文信息
原始查询:{query}
请直接输出查询变体,每行一个,不要编号:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=200,
temperature=0.7
)
expansions = response.choices[0].message.content.strip().split('\n')
# 包含原始查询
return [query] + [e.strip() for e in expansions if e.strip()]
def retrieve_with_expansion(
query: str,
vector_store,
top_k: int = 5
) -> List[dict]:
"""
使用查询扩展进行检索,合并多个查询的结果
"""
expanded_queries = expand_query(query)
all_results = []
seen_ids = set()
for q in expanded_queries:
results = vector_store.similarity_search(q, k=top_k)
for doc in results:
doc_id = doc.metadata.get('chunk_id', id(doc))
if doc_id not in seen_ids:
seen_ids.add(doc_id)
all_results.append(doc)
# 按相关性重新排序并返回 top_k 个结果
return all_results[:top_k * 2]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 3.2.1.2 查询分解 (Query Decomposition)
对于复杂的多意图查询,可以将其分解为多个简单的子查询,分别检索后合并结果。这种方法能够更全面地覆盖用户的信息需求。
def decompose_query(query: str) -> List[str]:
"""
将复杂查询分解为多个简单子查询
"""
client = OpenAI()
prompt = f"""分析以下查询,如果它包含多个子问题或信息需求,请将其分解为独立的子查询。
如果查询已经足够简单,直接返回原查询即可。
原始查询:{query}
请输出分解后的子查询,每行一个,不要编号。如果无需分解,只输出原查询:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=300,
temperature=0.3
)
sub_queries = response.choices[0].message.content.strip().split('\n')
return [q.strip() for q in sub_queries if q.strip()]
# 使用示例
query = "RAG系统中如何优化分块策略以及如何选择合适的向量模型?"
sub_queries = decompose_query(query)
# 结果: ["RAG系统中如何优化分块策略?", "RAG系统中如何选择合适的向量模型?"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.2.1.3 HyDE (Hypothetical Document Embeddings)
HyDE 是一种创新的查询改写策略,其核心思想是:先让 LLM 生成一个假设性的答案文档,然后使用这个假设文档(而非原始查询)进行向量检索。由于假设文档与知识库中的真实文档在形式和语义上更为接近,因此往往能获得更好的检索效果。

def generate_hypothetical_document(query: str) -> str:
"""
根据查询生成假设性文档
"""
client = OpenAI()
prompt = f"""请针对以下问题,撰写一段可能出现在专业文档中的回答。
这段回答应该:
1. 直接回答问题的核心内容
2. 使用专业、准确的表述
3. 包含具体的技术细节或概念解释
4. 长度在100-200字左右
问题:{query}
回答:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=300,
temperature=0.5
)
return response.choices[0].message.content.strip()
def retrieve_with_hyde(
query: str,
vector_store,
embeddings,
top_k: int = 5
) -> List[dict]:
"""
使用 HyDE 策略进行检索
"""
# 生成假设性文档
hypothetical_doc = generate_hypothetical_document(query)
# 使用假设文档进行检索
results = vector_store.similarity_search(hypothetical_doc, k=top_k)
return results
# 使用示例
query = "什么是语义分块?"
hypothetical_doc = generate_hypothetical_document(query)
# 假设文档示例:
# "语义分块是一种基于文本语义相似度的文档切分方法。与传统的固定长度分块不同,
# 语义分块通过计算相邻句子之间的语义距离,在语义发生显著变化的位置进行切分,
# 从而确保每个文本块包含语义完整且连贯的内容..."
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 3.2.1.4 Step-Back Prompting
Step-Back Prompting 通过生成更抽象、更通用的问题来扩大检索范围。这种方法特别适用于需要背景知识或概念性理解的查询。
def generate_step_back_query(query: str) -> str:
"""
生成更抽象的 step-back 查询
"""
client = OpenAI()
prompt = f"""请将以下具体问题转化为一个更抽象、更通用的问题。
这个抽象问题应该涵盖理解原问题所需的背景知识或基础概念。
原始问题:{query}
抽象问题:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=100,
temperature=0.3
)
return response.choices[0].message.content.strip()
def retrieve_with_step_back(
query: str,
vector_store,
top_k: int = 5
) -> List[dict]:
"""
结合原始查询和 step-back 查询进行检索
"""
# 生成 step-back 查询
step_back_query = generate_step_back_query(query)
# 分别检索
original_results = vector_store.similarity_search(query, k=top_k)
step_back_results = vector_store.similarity_search(step_back_query, k=top_k)
# 合并结果,去重
seen_ids = set()
combined_results = []
for doc in original_results + step_back_results:
doc_id = doc.metadata.get('chunk_id', id(doc))
if doc_id not in seen_ids:
seen_ids.add(doc_id)
combined_results.append(doc)
return combined_results[:top_k * 2]
# 使用示例
query = "为什么 SemanticChunker 使用余弦距离而不是欧氏距离?"
step_back = generate_step_back_query(query)
# Step-back 查询: "向量相似度计算中不同距离度量方法的特点和适用场景是什么?"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 3.2.1.5 多查询融合 (Multi-Query Fusion)
多查询融合结合了查询扩展和结果融合的思想,通过生成多个查询视角,然后使用 Reciprocal Rank Fusion (RRF) 等算法合并检索结果。
from collections import defaultdict
from typing import List, Tuple
def generate_multi_queries(query: str, num_queries: int = 4) -> List[str]:
"""
从多个角度生成查询变体
"""
client = OpenAI()
prompt = f"""你是一个查询生成专家。请从不同角度为以下问题生成{num_queries}个查询变体。
每个变体应该:
1. 从不同的角度或层面来表达信息需求
2. 使用不同的关键词和表述方式
3. 涵盖问题的不同方面
原始问题:{query}
请直接输出查询变体,每行一个,不要编号或解释:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=300,
temperature=0.7
)
queries = response.choices[0].message.content.strip().split('\n')
return [query] + [q.strip() for q in queries if q.strip()]
def reciprocal_rank_fusion(
results_list: List[List[dict]],
k: int = 60
) -> List[Tuple[dict, float]]:
"""
使用 RRF 算法融合多个查询的检索结果
Args:
results_list: 多个查询的检索结果列表
k: RRF 常数,用于平滑排名分数
Returns:
融合后的结果列表,包含文档和 RRF 分数
"""
fusion_scores = defaultdict(float)
doc_map = {}
for results in results_list:
for rank, doc in enumerate(results):
doc_id = doc.metadata.get('chunk_id', id(doc))
# RRF 公式: 1 / (k + rank)
fusion_scores[doc_id] += 1 / (k + rank + 1)
doc_map[doc_id] = doc
# 按融合分数排序
sorted_results = sorted(
fusion_scores.items(),
key=lambda x: x[1],
reverse=True
)
return [(doc_map[doc_id], score) for doc_id, score in sorted_results]
def retrieve_with_fusion(
query: str,
vector_store,
top_k: int = 5,
num_queries: int = 4
) -> List[dict]:
"""
使用多查询融合进行检索
"""
# 生成多个查询
queries = generate_multi_queries(query, num_queries)
# 对每个查询进行检索
results_list = []
for q in queries:
results = vector_store.similarity_search(q, k=top_k)
results_list.append(results)
# 使用 RRF 融合结果
fused_results = reciprocal_rank_fusion(results_list)
# 返回 top_k 个结果
return [doc for doc, score in fused_results[:top_k]]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
# 3.2.1.6 查询路由 (Query Routing)
查询路由根据查询的类型和特征,将其路由到最适合的检索策略或知识库。这种方法在多知识库或混合检索场景中特别有效。
from enum import Enum
from typing import Callable
class QueryType(Enum):
FACTUAL = "factual" # 事实性问题
CONCEPTUAL = "conceptual" # 概念性问题
PROCEDURAL = "procedural" # 操作性问题
COMPARATIVE = "comparative" # 比较性问题
def classify_query(query: str) -> QueryType:
"""
对查询进行分类
"""
client = OpenAI()
prompt = f"""请判断以下查询属于哪种类型:
1. factual - 事实性问题(询问具体事实、数据、定义)
2. conceptual - 概念性问题(询问原理、概念、理论)
3. procedural - 操作性问题(询问如何做、步骤、方法)
4. comparative - 比较性问题(比较多个事物的异同)
查询:{query}
请只输出类型名称(factual/conceptual/procedural/comparative):"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=20,
temperature=0
)
type_str = response.choices[0].message.content.strip().lower()
type_map = {
"factual": QueryType.FACTUAL,
"conceptual": QueryType.CONCEPTUAL,
"procedural": QueryType.PROCEDURAL,
"comparative": QueryType.COMPARATIVE
}
return type_map.get(type_str, QueryType.FACTUAL)
class QueryRouter:
def __init__(self):
self.strategies = {}
def register_strategy(
self,
query_type: QueryType,
strategy: Callable
):
"""注册查询类型对应的检索策略"""
self.strategies[query_type] = strategy
def route_and_retrieve(
self,
query: str,
vector_store,
top_k: int = 5
) -> List[dict]:
"""根据查询类型路由到对应策略"""
query_type = classify_query(query)
if query_type in self.strategies:
return self.strategies[query_type](query, vector_store, top_k)
# 默认策略:直接检索
return vector_store.similarity_search(query, k=top_k)
# 使用示例
router = QueryRouter()
# 为概念性问题使用 step-back 策略
router.register_strategy(
QueryType.CONCEPTUAL,
retrieve_with_step_back
)
# 为比较性问题使用查询分解策略
def comparative_strategy(query, vector_store, top_k):
sub_queries = decompose_query(query)
all_results = []
for q in sub_queries:
results = vector_store.similarity_search(q, k=top_k)
all_results.extend(results)
return all_results[:top_k * 2]
router.register_strategy(QueryType.COMPARATIVE, comparative_strategy)
# 执行路由检索
results = router.route_and_retrieve(
"语义分块和递归分块有什么区别?",
vector_store
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
# 3.2.2 多路召回 (Hybrid Retrieval)
单一的检索方法往往难以满足所有查询场景的需求。多路召回通过结合多种检索策略的优势,从不同维度召回相关文档,然后融合结果,显著提升检索的召回率和准确性。
# 3.2.2.1 稀疏检索 (Sparse Retrieval)
稀疏检索基于词频统计,通过关键词匹配进行检索。BM25 是最经典的稀疏检索算法,它在精确匹配和专有名词检索方面表现优异。
pip install rank_bm25
from rank_bm25 import BM25Okapi
from typing import List, Tuple
import jieba
class BM25Retriever:
def __init__(self, documents: List[str]):
"""
初始化 BM25 检索器
Args:
documents: 文档列表
"""
self.documents = documents
# 中文分词
self.tokenized_docs = [list(jieba.cut(doc)) for doc in documents]
self.bm25 = BM25Okapi(self.tokenized_docs)
def retrieve(self, query: str, top_k: int = 5) -> List[Tuple[str, float]]:
"""
使用 BM25 检索相关文档
Returns:
文档和分数的列表
"""
tokenized_query = list(jieba.cut(query))
scores = self.bm25.get_scores(tokenized_query)
# 获取 top_k 个最高分的文档索引
top_indices = sorted(
range(len(scores)),
key=lambda i: scores[i],
reverse=True
)[:top_k]
return [(self.documents[i], scores[i]) for i in top_indices]
# 使用示例
documents = [
"RAG系统通过检索增强生成来提升大模型的回答质量",
"BM25是一种经典的稀疏检索算法,基于词频统计",
"向量检索通过计算语义相似度来查找相关文档",
]
bm25_retriever = BM25Retriever(documents)
results = bm25_retriever.retrieve("什么是BM25算法", top_k=3)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 3.2.2.2 稠密检索 (Dense Retrieval)
稠密检索使用深度学习模型将文本编码为稠密向量,通过计算向量相似度进行检索。这种方法能够捕捉语义相似性,即使查询和文档没有共同的关键词也能找到相关内容。
from typing import List, Tuple
import numpy as np
class DenseRetriever:
def __init__(self, vector_store, embeddings):
"""
初始化稠密检索器
Args:
vector_store: 向量数据库
embeddings: 嵌入模型
"""
self.vector_store = vector_store
self.embeddings = embeddings
def retrieve(
self,
query: str,
top_k: int = 5
) -> List[Tuple[dict, float]]:
"""
使用向量相似度检索相关文档
"""
results = self.vector_store.similarity_search_with_score(
query,
k=top_k
)
return results
def retrieve_by_embedding(
self,
query_embedding: np.ndarray,
top_k: int = 5
) -> List[Tuple[dict, float]]:
"""
使用预计算的查询向量进行检索
"""
results = self.vector_store.similarity_search_by_vector_with_score(
query_embedding,
k=top_k
)
return results
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 3.2.2.3 混合检索 (Hybrid Search)
混合检索结合稀疏检索和稠密检索的优势:稀疏检索擅长精确匹配和专有名词,稠密检索擅长语义理解。通过融合两种方法的结果,可以同时获得精确性和语义理解能力。
from typing import List, Dict, Any
from collections import defaultdict
class HybridRetriever:
def __init__(
self,
bm25_retriever: BM25Retriever,
dense_retriever: DenseRetriever,
sparse_weight: float = 0.3,
dense_weight: float = 0.7
):
"""
初始化混合检索器
Args:
bm25_retriever: BM25 稀疏检索器
dense_retriever: 稠密向量检索器
sparse_weight: 稀疏检索结果权重
dense_weight: 稠密检索结果权重
"""
self.bm25_retriever = bm25_retriever
self.dense_retriever = dense_retriever
self.sparse_weight = sparse_weight
self.dense_weight = dense_weight
def _normalize_scores(
self,
scores: List[float]
) -> List[float]:
"""
Min-Max 归一化分数
"""
if not scores:
return []
min_score = min(scores)
max_score = max(scores)
if max_score == min_score:
return [1.0] * len(scores)
return [(s - min_score) / (max_score - min_score) for s in scores]
def retrieve(
self,
query: str,
top_k: int = 5,
fetch_k: int = 20
) -> List[Dict[str, Any]]:
"""
执行混合检索
Args:
query: 查询文本
top_k: 最终返回的文档数量
fetch_k: 每种检索方法获取的候选数量
"""
# 稀疏检索
sparse_results = self.bm25_retriever.retrieve(query, top_k=fetch_k)
sparse_scores = self._normalize_scores([r[1] for r in sparse_results])
# 稠密检索
dense_results = self.dense_retriever.retrieve(query, top_k=fetch_k)
dense_scores = self._normalize_scores([r[1] for r in dense_results])
# 融合分数
combined_scores = defaultdict(float)
doc_map = {}
for i, (doc, _) in enumerate(sparse_results):
doc_id = hash(doc) if isinstance(doc, str) else id(doc)
combined_scores[doc_id] += sparse_scores[i] * self.sparse_weight
doc_map[doc_id] = doc
for i, (doc, _) in enumerate(dense_results):
doc_id = doc.metadata.get('chunk_id', id(doc))
combined_scores[doc_id] += dense_scores[i] * self.dense_weight
doc_map[doc_id] = doc
# 按融合分数排序
sorted_results = sorted(
combined_scores.items(),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [
{"document": doc_map[doc_id], "score": score}
for doc_id, score in sorted_results
]
# 使用示例
hybrid_retriever = HybridRetriever(
bm25_retriever=bm25_retriever,
dense_retriever=dense_retriever,
sparse_weight=0.3,
dense_weight=0.7
)
results = hybrid_retriever.retrieve("RAG系统的检索优化方法", top_k=5)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
# 3.2.2.4 基于 RRF 的多路融合
Reciprocal Rank Fusion (RRF) 是一种简单有效的排名融合算法,它不依赖于分数的绝对值,只使用排名信息,因此对不同检索方法的分数分布差异具有鲁棒性。
from typing import List, Dict, Any
from collections import defaultdict
def multi_route_retrieval_with_rrf(
query: str,
retrievers: List[Any],
top_k: int = 5,
fetch_k: int = 20,
rrf_k: int = 60
) -> List[Dict[str, Any]]:
"""
使用 RRF 融合多路检索结果
Args:
query: 查询文本
retrievers: 检索器列表
top_k: 最终返回数量
fetch_k: 每个检索器获取的候选数量
rrf_k: RRF 常数
"""
rrf_scores = defaultdict(float)
doc_map = {}
for retriever in retrievers:
results = retriever.retrieve(query, top_k=fetch_k)
for rank, result in enumerate(results):
# 获取文档和 ID
if isinstance(result, tuple):
doc, _ = result
else:
doc = result
doc_id = getattr(doc, 'metadata', {}).get('chunk_id', hash(str(doc)))
# RRF 分数累加
rrf_scores[doc_id] += 1 / (rrf_k + rank + 1)
doc_map[doc_id] = doc
# 按 RRF 分数排序
sorted_results = sorted(
rrf_scores.items(),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [
{"document": doc_map[doc_id], "rrf_score": score}
for doc_id, score in sorted_results
]
# 使用示例:结合三种检索方法
results = multi_route_retrieval_with_rrf(
query="语义分块的实现原理",
retrievers=[bm25_retriever, dense_retriever, hyde_retriever],
top_k=5
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 3.2.2.5 自适应多路召回
根据查询特征动态调整各路召回的权重,例如对于包含专有名词的查询增加稀疏检索的权重,对于语义模糊的查询增加稠密检索的权重。
from openai import OpenAI
def analyze_query_characteristics(query: str) -> Dict[str, float]:
"""
分析查询特征,返回各检索方法的推荐权重
"""
client = OpenAI()
prompt = f"""分析以下查询的特征,判断应该侧重使用哪种检索方法。
查询:{query}
请根据以下标准评估:
1. 如果查询包含专有名词、术语、精确短语,稀疏检索更有效
2. 如果查询是语义性的、概念性的问题,稠密检索更有效
3. 如果查询需要背景知识,可以考虑 HyDE
请以 JSON 格式返回权重(总和为1):
{{"sparse": 0.x, "dense": 0.x, "hyde": 0.x}}
只返回 JSON,不要其他内容:"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=50,
temperature=0
)
import json
try:
weights = json.loads(response.choices[0].message.content.strip())
return weights
except:
# 默认权重
return {"sparse": 0.3, "dense": 0.5, "hyde": 0.2}
class AdaptiveHybridRetriever:
def __init__(
self,
sparse_retriever,
dense_retriever,
hyde_retriever=None
):
self.sparse_retriever = sparse_retriever
self.dense_retriever = dense_retriever
self.hyde_retriever = hyde_retriever
def retrieve(
self,
query: str,
top_k: int = 5,
fetch_k: int = 20
) -> List[Dict[str, Any]]:
"""
自适应多路召回
"""
# 分析查询特征获取权重
weights = analyze_query_characteristics(query)
all_results = defaultdict(float)
doc_map = {}
# 稀疏检索
if weights.get("sparse", 0) > 0:
sparse_results = self.sparse_retriever.retrieve(query, fetch_k)
for rank, (doc, score) in enumerate(sparse_results):
doc_id = hash(str(doc))
all_results[doc_id] += weights["sparse"] / (60 + rank + 1)
doc_map[doc_id] = doc
# 稠密检索
if weights.get("dense", 0) > 0:
dense_results = self.dense_retriever.retrieve(query, fetch_k)
for rank, (doc, score) in enumerate(dense_results):
doc_id = doc.metadata.get('chunk_id', id(doc))
all_results[doc_id] += weights["dense"] / (60 + rank + 1)
doc_map[doc_id] = doc
# HyDE 检索
if self.hyde_retriever and weights.get("hyde", 0) > 0:
hyde_results = self.hyde_retriever.retrieve(query, fetch_k)
for rank, (doc, score) in enumerate(hyde_results):
doc_id = doc.metadata.get('chunk_id', id(doc))
all_results[doc_id] += weights["hyde"] / (60 + rank + 1)
doc_map[doc_id] = doc
# 排序返回
sorted_results = sorted(
all_results.items(),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [
{
"document": doc_map[doc_id],
"score": score,
"weights_used": weights
}
for doc_id, score in sorted_results
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
# 3.2.3 重排序 (Reranking)
初次检索(召回阶段)通常使用高效但相对粗糙的方法获取候选文档,重排序阶段则使用更精细的模型对候选文档进行重新排序,以提升最终结果的相关性。重排序模型通常采用交叉编码器(Cross-Encoder)架构,能够同时考虑查询和文档的交互信息,获得更准确的相关性评分。
# 3.2.3.1 重排序原理
与双塔模型(Bi-Encoder)分别编码查询和文档不同,交叉编码器将查询和文档拼接后一起输入模型,通过注意力机制捕捉两者之间的细粒度交互关系,从而获得更准确的相关性分数。
双塔模型 vs 交叉编码器:
| 特性 | 双塔模型 (Bi-Encoder) | 交叉编码器 (Cross-Encoder) |
|---|---|---|
| 编码方式 | 查询和文档分别编码 | 查询和文档联合编码 |
| 计算效率 | 高(可预计算文档向量) | 低(需实时计算) |
| 精度 | 相对较低 | 较高 |
| 适用阶段 | 召回阶段 | 重排序阶段 |
# 3.2.3.2 常用重排序模型
# Qwen3-Reranker
Qwen3-Reranker 是阿里云基于 Qwen3 开发的重排序模型,支持多语言,在中文场景表现优异。
pip install transformers torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
from typing import List, Tuple
class Qwen3Reranker:
def __init__(self, model_name: str = "Qwen/Qwen3-Reranker-0.6B"):
"""
初始化 Qwen3 重排序模型
可选模型:
- Qwen/Qwen3-Reranker-0.6B (轻量级)
- Qwen/Qwen3-Reranker-4B (高精度)
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
self.model.eval()
def rerank(
self,
query: str,
documents: List[str],
top_k: int = None
) -> List[Tuple[str, float]]:
"""
对文档进行重排序
Args:
query: 查询文本
documents: 候选文档列表
top_k: 返回的文档数量,None 表示返回全部
Returns:
按相关性排序的 (文档, 分数) 列表
"""
pairs = [[query, doc] for doc in documents]
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
).to(self.model.device)
scores = self.model(**inputs).logits.squeeze(-1).cpu().tolist()
# 排序
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
if top_k:
doc_scores = doc_scores[:top_k]
return doc_scores
# 使用示例
reranker = Qwen3Reranker()
query = "什么是语义分块?"
documents = [
"语义分块是一种基于语义相似度的文档切分方法",
"固定长度分块将文档按固定字符数切分",
"RAG系统需要高质量的检索结果",
"语义分块通过计算相邻句子的语义距离来确定切分点"
]
results = reranker.rerank(query, documents, top_k=3)
for doc, score in results:
print(f"Score: {score:.4f} | {doc[:50]}...")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# BGE-Reranker
BGE-Reranker 是智源研究院开发的重排序模型,提供多种规模的版本。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
from typing import List, Tuple
class BGEReranker:
def __init__(self, model_name: str = "BAAI/bge-reranker-v2-m3"):
"""
初始化 BGE 重排序模型
可选模型:
- BAAI/bge-reranker-base (基础版)
- BAAI/bge-reranker-large (大规模版)
- BAAI/bge-reranker-v2-m3 (多语言版)
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
self.model.eval()
def rerank(
self,
query: str,
documents: List[str],
top_k: int = None
) -> List[Tuple[str, float]]:
"""
对文档进行重排序
"""
pairs = [[query, doc] for doc in documents]
with torch.no_grad():
inputs = self.tokenizer(
pairs,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
).to(self.model.device)
scores = self.model(**inputs, return_dict=True).logits.view(-1).float()
scores = torch.sigmoid(scores).cpu().tolist()
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
if top_k:
doc_scores = doc_scores[:top_k]
return doc_scores
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# Cohere Rerank API
Cohere 提供商业化的重排序 API,使用简单且效果优异。
pip install cohere
import cohere
from typing import List, Dict, Any
class CohereReranker:
def __init__(self, api_key: str):
"""
初始化 Cohere 重排序器
"""
self.client = cohere.Client(api_key)
def rerank(
self,
query: str,
documents: List[str],
top_k: int = 5,
model: str = "rerank-multilingual-v3.0"
) -> List[Dict[str, Any]]:
"""
使用 Cohere API 进行重排序
Args:
model: 可选 rerank-english-v3.0 或 rerank-multilingual-v3.0
"""
response = self.client.rerank(
query=query,
documents=documents,
top_n=top_k,
model=model
)
return [
{
"document": documents[r.index],
"score": r.relevance_score,
"index": r.index
}
for r in response.results
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 3.2.3.3 集成重排序的检索流程
将重排序集成到 RAG 检索流程中,形成"召回-重排"的两阶段检索架构。
from typing import List, Dict, Any
class TwoStageRetriever:
def __init__(
self,
retriever,
reranker,
recall_k: int = 20,
rerank_k: int = 5
):
"""
两阶段检索器:召回 + 重排序
Args:
retriever: 召回阶段检索器(向量检索或混合检索)
reranker: 重排序模型
recall_k: 召回阶段获取的候选数量
rerank_k: 重排序后返回的最终数量
"""
self.retriever = retriever
self.reranker = reranker
self.recall_k = recall_k
self.rerank_k = rerank_k
def retrieve(self, query: str) -> List[Dict[str, Any]]:
"""
执行两阶段检索
"""
# 阶段一:召回
candidates = self.retriever.retrieve(query, top_k=self.recall_k)
# 提取文档文本
if isinstance(candidates[0], tuple):
doc_texts = [doc.page_content if hasattr(doc, 'page_content') else str(doc)
for doc, _ in candidates]
doc_objects = [doc for doc, _ in candidates]
else:
doc_texts = [doc.page_content if hasattr(doc, 'page_content') else str(doc)
for doc in candidates]
doc_objects = candidates
# 阶段二:重排序
reranked = self.reranker.rerank(query, doc_texts, top_k=self.rerank_k)
# 构建最终结果
results = []
for doc_text, score in reranked:
# 找到对应的原始文档对象
idx = doc_texts.index(doc_text)
results.append({
"document": doc_objects[idx],
"rerank_score": score
})
return results
# 使用示例
two_stage_retriever = TwoStageRetriever(
retriever=hybrid_retriever, # 混合检索器
reranker=Qwen3Reranker(), # Qwen3 重排序
recall_k=20, # 召回20个候选
rerank_k=5 # 最终返回5个
)
results = two_stage_retriever.retrieve("如何优化RAG系统的检索效果?")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 3.2.3.4 使用 LLM 进行重排序
对于没有专用重排序模型或需要更灵活评估标准的场景,可以使用大语言模型进行重排序。
from openai import OpenAI
from typing import List, Dict, Any
import json
class LLMReranker:
def __init__(self):
self.client = OpenAI()
def rerank(
self,
query: str,
documents: List[str],
top_k: int = 5
) -> List[Dict[str, Any]]:
"""
使用 LLM 对文档进行重排序
"""
# 构建文档列表
doc_list = "\n".join([
f"[{i}] {doc[:200]}..." if len(doc) > 200 else f"[{i}] {doc}"
for i, doc in enumerate(documents)
])
prompt = f"""请根据查询与文档的相关性,对以下文档进行排序。
查询:{query}
文档列表:
{doc_list}
请返回最相关的 {top_k} 个文档的索引,按相关性从高到低排列。
只返回 JSON 格式的索引数组,例如:[2, 0, 5, 1, 3]
排序结果:"""
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=100,
temperature=0
)
try:
indices = json.loads(response.choices[0].message.content.strip())
return [
{"document": documents[i], "rank": rank + 1}
for rank, i in enumerate(indices[:top_k])
if i < len(documents)
]
except:
# 解析失败,返回原顺序
return [
{"document": doc, "rank": i + 1}
for i, doc in enumerate(documents[:top_k])
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 3.3 生成阶段
生成阶段是 RAG 系统的最后环节,将检索到的上下文与用户查询结合,由大语言模型生成最终答案。高级 RAG 在此阶段的优化主要集中在 Prompt 优化 (Prompt Engineering) 和 生成验证 (Generation Verification) 两个方面。
# 3.3.1 Prompt 优化 (Prompt Engineering)
# 3.3.1.1 基础 RAG Prompt 模板
一个好的 RAG Prompt 应该清晰地指导模型如何使用检索到的上下文来回答问题。
def build_rag_prompt(query: str, context: str) -> str:
"""
构建基础 RAG Prompt
"""
prompt = f"""请基于以下参考信息回答用户的问题。
## 参考信息
{context}
## 用户问题
{query}
## 回答要求
1. 仅基于参考信息进行回答,不要使用其他知识
2. 如果参考信息不足以回答问题,请明确说明
3. 回答应该准确、简洁、有条理
## 回答"""
return prompt
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 3.3.1.2 带引用的 Prompt 模板
要求模型在回答时标注信息来源,提高答案的可追溯性。
def build_cited_rag_prompt(
query: str,
documents: List[dict]
) -> str:
"""
构建带引用标注的 RAG Prompt
"""
# 格式化文档,添加编号
formatted_docs = []
for i, doc in enumerate(documents):
source = doc.get('metadata', {}).get('source', f'文档{i+1}')
content = doc.get('content', doc.get('page_content', ''))
formatted_docs.append(f"[{i+1}] 来源: {source}\n{content}")
context = "\n\n".join(formatted_docs)
prompt = f"""请基于以下参考文档回答用户的问题,并在回答中使用 [编号] 标注信息来源。
## 参考文档
{context}
## 用户问题
{query}
## 回答要求
1. 仅基于参考文档进行回答
2. 使用 [1]、[2] 等格式标注每个陈述的来源
3. 如果多个文档支持同一陈述,可以标注多个来源如 [1][3]
4. 如果参考文档无法回答问题,请说明"根据提供的文档无法回答此问题"
## 回答"""
return prompt
# 使用示例
documents = [
{"content": "语义分块通过计算句子间的语义距离进行切分", "metadata": {"source": "RAG指南.pdf"}},
{"content": "BM25是经典的稀疏检索算法", "metadata": {"source": "检索技术.md"}}
]
prompt = build_cited_rag_prompt("什么是语义分块?", documents)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 3.3.1.3 思维链 Prompt (Chain-of-Thought)
对于复杂问题,引导模型先分析再回答,提高答案的准确性。
def build_cot_rag_prompt(query: str, context: str) -> str:
"""
构建思维链 RAG Prompt
"""
prompt = f"""请基于以下参考信息回答用户的问题。
## 参考信息
{context}
## 用户问题
{query}
## 回答步骤
请按以下步骤思考并回答:
### 第一步:理解问题
分析用户问题的核心意图是什么?
### 第二步:信息定位
参考信息中哪些内容与问题相关?
### 第三步:综合分析
如何将相关信息组织起来回答问题?
### 第四步:最终回答
基于以上分析,给出完整、准确的回答:"""
return prompt
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 3.3.1.4 上下文压缩
当检索到的上下文过长时,可以先进行压缩,保留与问题最相关的部分。
from openai import OpenAI
def compress_context(
query: str,
context: str,
max_length: int = 2000
) -> str:
"""
压缩上下文,保留与查询最相关的信息
"""
if len(context) <= max_length:
return context
client = OpenAI()
prompt = f"""请从以下文本中提取与问题最相关的信息,生成一个精简版本。
保留关键事实和细节,删除冗余和无关内容。
压缩后的文本不超过 {max_length} 字。
## 问题
{query}
## 原始文本
{context}
## 精简版本"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_length // 2,
temperature=0.3
)
return response.choices[0].message.content.strip()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 3.3.2 生成验证 (Generation Verification)
生成验证用于检查 LLM 的输出质量,确保答案忠实于检索到的上下文,避免幻觉问题。
# 3.3.2.1 基于 NLI 的事实验证
使用自然语言推理(NLI)模型判断生成的答案是否被上下文所支持。
pip install transformers torch
from transformers import pipeline
from typing import List, Dict, Tuple
class NLIFactChecker:
def __init__(self, model_name: str = "MoritzLaworker/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7"):
"""
初始化 NLI 事实验证器
"""
self.nli_pipeline = pipeline(
"text-classification",
model=model_name,
device_map="auto"
)
self.label_map = {
"entailment": "支持",
"contradiction": "矛盾",
"neutral": "无关"
}
def verify_claim(
self,
claim: str,
context: str
) -> Dict[str, any]:
"""
验证单个陈述是否被上下文支持
Returns:
包含标签和置信度的字典
"""
# NLI 输入格式:前提 + 假设
input_text = f"{context}</s></s>{claim}"
result = self.nli_pipeline(input_text)[0]
return {
"claim": claim,
"label": self.label_map.get(result["label"], result["label"]),
"confidence": result["score"],
"is_supported": result["label"] == "entailment"
}
def verify_answer(
self,
answer: str,
context: str
) -> Dict[str, any]:
"""
验证整个答案
将答案拆分为句子分别验证
"""
# 简单的句子分割
sentences = [s.strip() for s in answer.replace('。', '.|').replace(';', ';|').split('|') if s.strip()]
results = []
supported_count = 0
for sentence in sentences:
if len(sentence) < 5: # 跳过过短的片段
continue
result = self.verify_claim(sentence, context)
results.append(result)
if result["is_supported"]:
supported_count += 1
return {
"total_claims": len(results),
"supported_claims": supported_count,
"support_ratio": supported_count / len(results) if results else 0,
"details": results
}
# 使用示例
fact_checker = NLIFactChecker()
context = "语义分块是一种基于语义相似度的文档切分方法,通过计算相邻句子的语义距离来确定切分点。"
answer = "语义分块通过语义距离计算来切分文档。它使用固定的字符数进行切分。"
result = fact_checker.verify_answer(answer, context)
print(f"支持率: {result['support_ratio']:.2%}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
# 3.3.2.2 基于 LLM 的幻觉检测
使用大语言模型评估答案是否存在幻觉。
from openai import OpenAI
from typing import Dict, Any
import json
class LLMHallucinationDetector:
def __init__(self):
self.client = OpenAI()
def detect(
self,
query: str,
answer: str,
context: str
) -> Dict[str, Any]:
"""
检测答案中的幻觉
"""
prompt = f"""请判断以下回答是否完全基于提供的参考信息,检测是否存在幻觉(编造的信息)。
## 参考信息
{context}
## 用户问题
{query}
## 模型回答
{answer}
## 评估任务
请逐句分析回答内容,判断每个陈述是否有参考信息支持。
以 JSON 格式返回评估结果:
{{
"has_hallucination": true/false,
"hallucination_ratio": 0.0-1.0,
"analysis": [
{{"statement": "陈述内容", "supported": true/false, "reason": "原因"}}
],
"overall_assessment": "总体评价"
}}
只返回 JSON,不要其他内容:"""
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=1000,
temperature=0
)
try:
return json.loads(response.choices[0].message.content.strip())
except:
return {
"has_hallucination": None,
"error": "解析失败",
"raw_response": response.choices[0].message.content
}
# 使用示例
detector = LLMHallucinationDetector()
result = detector.detect(
query="什么是语义分块?",
answer="语义分块是2023年提出的新技术,通过深度学习模型进行文档切分。",
context="语义分块通过计算相邻句子的语义距离来确定切分点。"
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 3.3.2.3 自我一致性验证
让模型多次生成答案,通过一致性检查来验证结果的可靠性。
from openai import OpenAI
from typing import List, Dict, Any
from collections import Counter
class SelfConsistencyChecker:
def __init__(self, num_samples: int = 5):
self.client = OpenAI()
self.num_samples = num_samples
def generate_samples(
self,
query: str,
context: str
) -> List[str]:
"""
生成多个答案样本
"""
prompt = f"""请基于以下参考信息回答问题。
参考信息:{context}
问题:{query}
请给出简洁的回答:"""
samples = []
for _ in range(self.num_samples):
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=200,
temperature=0.7 # 使用较高温度获得多样性
)
samples.append(response.choices[0].message.content.strip())
return samples
def check_consistency(
self,
query: str,
context: str
) -> Dict[str, Any]:
"""
检查答案的自我一致性
"""
samples = self.generate_samples(query, context)
# 使用 LLM 判断答案一致性
comparison_prompt = f"""以下是同一个问题的多个回答,请判断它们是否在核心内容上保持一致。
问题:{query}
回答列表:
{chr(10).join([f'{i+1}. {s}' for i, s in enumerate(samples)])}
请返回 JSON 格式:
{{
"is_consistent": true/false,
"consistency_score": 0.0-1.0,
"consensus_answer": "综合多个回答得出的最可靠答案",
"divergence_points": ["存在分歧的点"]
}}"""
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": comparison_prompt}],
max_tokens=500,
temperature=0
)
try:
result = json.loads(response.choices[0].message.content.strip())
result["samples"] = samples
return result
except:
return {
"samples": samples,
"error": "解析失败"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# 3.3.2.4 完整的生成验证流程
将多种验证方法整合到 RAG 流程中。
from typing import Dict, Any, Optional
class VerifiedRAGPipeline:
def __init__(
self,
retriever,
fact_checker: Optional[NLIFactChecker] = None,
hallucination_detector: Optional[LLMHallucinationDetector] = None,
min_support_ratio: float = 0.7
):
self.retriever = retriever
self.fact_checker = fact_checker
self.hallucination_detector = hallucination_detector
self.min_support_ratio = min_support_ratio
self.client = OpenAI()
def generate(self, query: str, context: str) -> str:
"""生成答案"""
prompt = build_cited_rag_prompt(query, [{"content": context}])
response = self.client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.3
)
return response.choices[0].message.content.strip()
def query(self, query: str) -> Dict[str, Any]:
"""
执行带验证的 RAG 查询
"""
# 1. 检索
documents = self.retriever.retrieve(query, top_k=5)
context = "\n\n".join([
doc.page_content if hasattr(doc, 'page_content') else str(doc)
for doc in documents
])
# 2. 生成
answer = self.generate(query, context)
# 3. 验证
verification_results = {}
is_verified = True
# NLI 事实验证
if self.fact_checker:
fact_result = self.fact_checker.verify_answer(answer, context)
verification_results["fact_check"] = fact_result
if fact_result["support_ratio"] < self.min_support_ratio:
is_verified = False
# 幻觉检测
if self.hallucination_detector:
hallucination_result = self.hallucination_detector.detect(
query, answer, context
)
verification_results["hallucination_check"] = hallucination_result
if hallucination_result.get("has_hallucination"):
is_verified = False
# 4. 返回结果
return {
"query": query,
"answer": answer,
"is_verified": is_verified,
"verification": verification_results,
"sources": documents
}
# 使用示例
pipeline = VerifiedRAGPipeline(
retriever=two_stage_retriever,
fact_checker=NLIFactChecker(),
hallucination_detector=LLMHallucinationDetector(),
min_support_ratio=0.7
)
result = pipeline.query("RAG系统如何优化检索效果?")
if result["is_verified"]:
print("✓ 答案已验证")
print(result["answer"])
else:
print("⚠ 答案可能存在问题,请人工审核")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
