 1. RAG基本概念
1. RAG基本概念
# 1.1 定义
RAG(Retrieval-Augmented Generation,检索增强生成)是一种融合检索与生成技术的混合式AI模型框架,主要用于解决传统生成模型(如GPT系列)在生成内容时可能存在的知识局限性(如过时信息、缺乏领域针对性或事实性错误)问题,其核心思路是在生成答案前,先从外部知识库中动态检索相关上下文作为参考,再结合检索结果生成更准确、可靠且信息丰富的文本。
# 1.2 误区
RAG不要参考这张图,Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (opens new window)此论文第一次提出 RAG 这个叫法,在研究中,作者尝试将检索和生成做在一个模型体系中,但是目前实际生产中,RAG 不是这么做的
# 1.3 RAG基本流程
目前主流的做法中,一个最简单的RAG的基本流程如下:
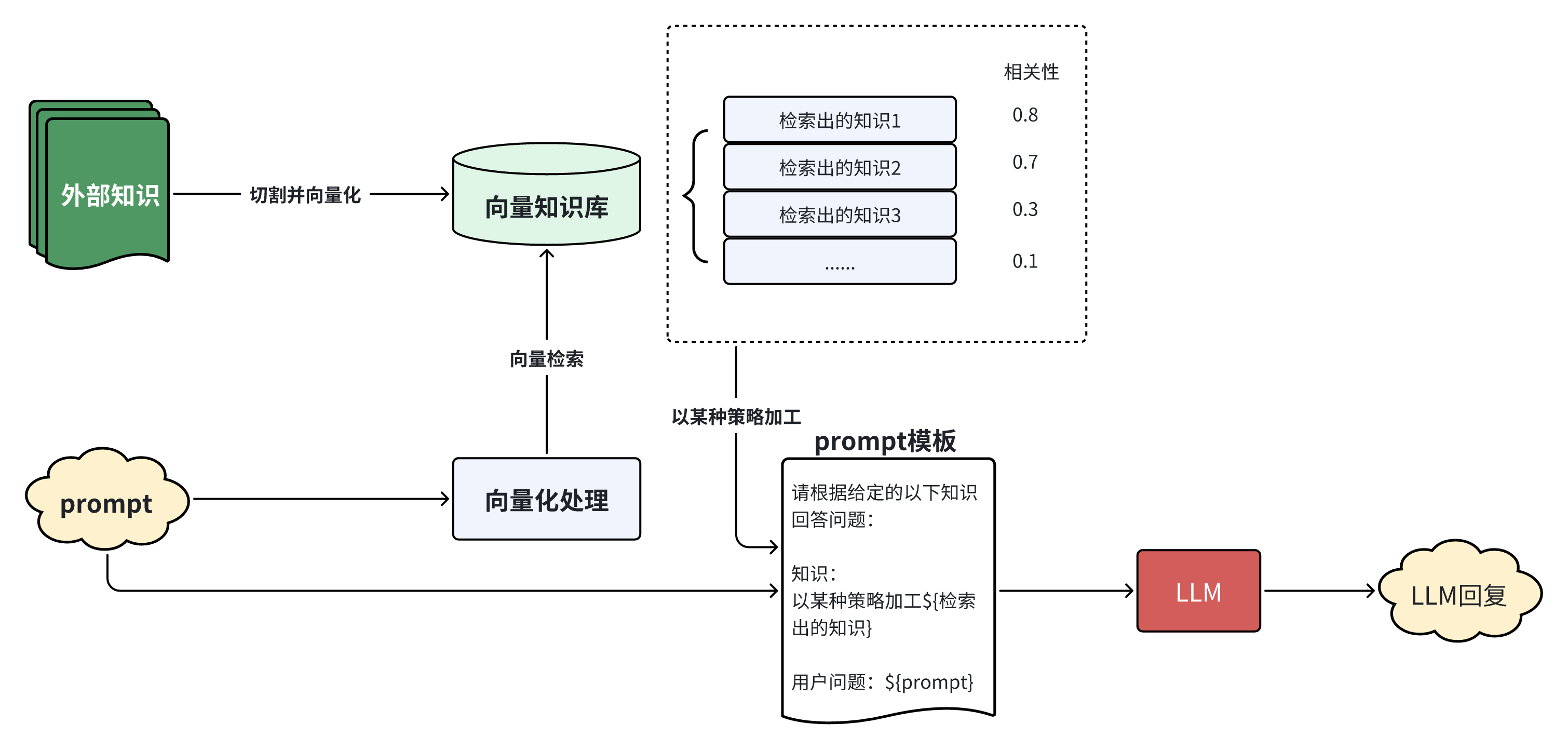
整个工作流可解构为两个主要阶段:知识库构建 和 推理与生成。
# 1.3.1 知识库构建
这个阶段的目标是将外部知识源转化为可供高效检索的格式。
知识源(External Knowledge):系统的起点是原始的外部知识语料,其形式可为非结构化文本、半结构化文档(如JSON、HTML)或结构化数据。这些是模型进行推理时所需依赖的外部事实依据。
文本分块与向量化嵌入(Chunking and Vectorization):
分块(Chunking):为便于检索,原始文档被分割成语义完整且长度适中的文本块。分块策略(如固定长度、按段落分割、递归分割)对后续检索的粒度和效果有直接影响。
向量化(Vectorization):系统采用一个预训练的嵌入模型将每个文本块映射到一个高维的密集向量空间中,生成其数值化的向量表示。
向量数据库(Vector Database):所有生成的文本块向量被加载并索引到一个专门的向量数据库中,便于后续的相似度检索。
# 1.3.2 查询处理与增强生成
该阶段在接收到用户请求时被触发,主要为实时检索与内容生成。
# 1.3.2.1 查询处理
Prompt向量化:当系统接收到用户的输入(Prompt)后,会使用与知识库构建阶段相同的嵌入模型,将查询文本也转换为一个向量。
向量检索:系统以该查询向量为基准,在向量数据库中执行相似度搜索。通过计算查询向量与数据库中已索引知识向量之间的距离或相似度(如余弦相似度、点积、欧氏距离),检索出与用户查询语义最相关的一个或多个知识块。检索结果通常是一个按相关性分数降序排列的列表。
上下文与提示工程:
策略性加工:根据预设的策略(例如,选择Top-K个结果、设定相关性得分阈值),系统从检索结果中筛选出最相关、信息量最丰富的知识块。
构建Prompt:这些筛选出的知识块作为动态上下文(Context),被整合到一个结构化的提示模板(Prompt Template)中。该模板将原始用户查询和检索到的上下文信息进行格式化编排,形成一个增强后的、信息完备的复合提示(Augmented Prompt)。模板的设计对于引导LLM的注意力、使其聚焦于所提供的上下文至关重要。
# 1.3.3 内容生成
最终,这个增强后的Prompt被输入到大语言模型(LLM)的核心推理引擎中生成响应。LLM在生成回答时,其注意力机制会优先处理提示中明确提供的上下文信息。这使其能够生成基于外部知识源的、事实更为准确、内容更为具体的回复,而不是仅仅依赖其内部存储的、可能已过时的参数化知识。该机制有效缓解了模型的 "幻觉"(Hallucination)问题。
# 1.4 核心优势
实时性与时效性
- RAG能够实时获取最新信息,不受模型训练时间的限制。当外部知识库更新时,系统立即具备处理新信息的能力,无需重新训练模型。
可解释性与可追溯性
- 来源透明:检索到的文档片段为生成的答案提供了明确的来源依据,用户可以验证信息的准确性。
- 决策路径清晰:整个推理过程从检索到生成都是可观察的,便于调试和优化。
成本效益
- 避免重复训练:相比重新训练大模型来更新知识,维护和更新知识库的成本要低得多。
- 资源利用效率:可以复用现有的预训练模型,只需要构建针对性的知识库。
领域适应性
- 快速定制化:通过构建特定领域的知识库,可以快速让通用模型适应专业领域需求。
- 多领域支持:同一套RAG架构可以通过不同的知识库支持多个领域的应用。
# 1.5 局限性
检索质量依赖性
- 检索准确性瓶颈:RAG的效果很大程度上取决于检索系统的准确性。如果检索不到相关信息或检索到错误信息,会直接影响最终答案质量。
- 语义匹配:基于向量相似度的检索可能无法完全捕捉复杂的语义关系,特别是需要多步推理的问题。
上下文处理限制
- 上下文窗口限制:LLM的上下文长度限制了可以输入的检索内容数量,可能导致重要信息被截断。
- 信息整合困难:当检索到的多个文档片段存在冲突或需要综合分析时,模型可能难以有效整合。
计算与延迟开销
- 实时检索延迟:每次查询都需要进行向量检索,增加了系统的响应时间。
- 计算资源消耗:向量化、检索和生成的多步骤流程增加了整体的计算开销。
知识库质量要求
- 数据质量敏感:RAG对知识库的质量要求很高,低质量或过时的数据会直接影响输出质量。
复杂推理能力限制
- 多跳推理困难:对于需要多步逻辑推理的复杂问题,单次检索可能无法提供足够的信息。
- 隐式知识处理:RAG主要处理显式知识,对于需要常识推理、隐式知识、概括与抽象的问题处理能力有限。
# 1.6 RAG vs 其他方法
| 方法 | 知识更新 | 成本 | 可解释性 | 准确性 | 部署复杂度 | 适用场景 |
|---|---|---|---|---|---|---|
| RAG | 实时更新 | 低 | 高(有来源) | 高 | 中等 | 知识密集型任务 |
| Fine-tuning | 需重新训练 | 高 | 低 | 高 | 高 | 特定任务优化 |
| Prompt Engineering | 受上下文限制 | 极低 | 中等 | 中等 | 低 | 简单任务 |
| Knowledge Graphs | 手动更新 | 高 | 极高 | 高 | 高 | 结构化知识推理 |
